0609-在系统中查找重复文件
给你一个目录信息列表 paths ,包括目录路径,以及该目录中的所有文件及其内容,请你按路径返回文件系统中的所有重复文件。答案可按 任意顺序
返回。
一组重复的文件至少包括 两个 具有完全相同内容的文件。
输入 列表中的单个目录信息字符串的格式如下:
"root/d1/d2/.../dm f1.txt(f1_content) f2.txt(f2_content) ... fn.txt(fn_content)"
这意味着,在目录 root/d1/d2/.../dm 下,有 n 个文件 ( f1.txt, f2.txt … fn.txt )
的内容分别是 ( f1_content, f2_content … fn_content ) 。注意:n >= 1 且 m >= 0
。如果 m = 0 ,则表示该目录是根目录。
输出 是由 重复文件路径组 构成的列表。其中每个组由所有具有相同内容文件的文件路径组成。文件路径是具有下列格式的字符串:
"directory_path/file_name.txt"
示例 1:
**输入:** paths = ["root/a 1.txt(abcd) 2.txt(efgh)","root/c 3.txt(abcd)","root/c/d 4.txt(efgh)","root 4.txt(efgh)"]
**输出:** [["root/a/2.txt","root/c/d/4.txt","root/4.txt"],["root/a/1.txt","root/c/3.txt"]]
示例 2:
**输入:** paths = ["root/a 1.txt(abcd) 2.txt(efgh)","root/c 3.txt(abcd)","root/c/d 4.txt(efgh)"]
**输出:** [["root/a/2.txt","root/c/d/4.txt"],["root/a/1.txt","root/c/3.txt"]]
提示:
1 <= paths.length <= 2 * 1041 <= paths[i].length <= 30001 <= sum(paths[i].length) <= 5 * 105paths[i]由英文字母、数字、字符'/'、'.'、'('、')'和' '组成- 你可以假设在同一目录中没有任何文件或目录共享相同的名称。
- 你可以假设每个给定的目录信息代表一个唯一的目录。目录路径和文件信息用单个空格分隔。
进阶:
- 假设您有一个真正的文件系统,您将如何搜索文件?广度搜索还是宽度搜索?
- 如果文件内容非常大(GB级别),您将如何修改您的解决方案?
- 如果每次只能读取 1 kb 的文件,您将如何修改解决方案?
- 修改后的解决方案的时间复杂度是多少?其中最耗时的部分和消耗内存的部分是什么?如何优化?
- 如何确保您发现的重复文件不是误报?
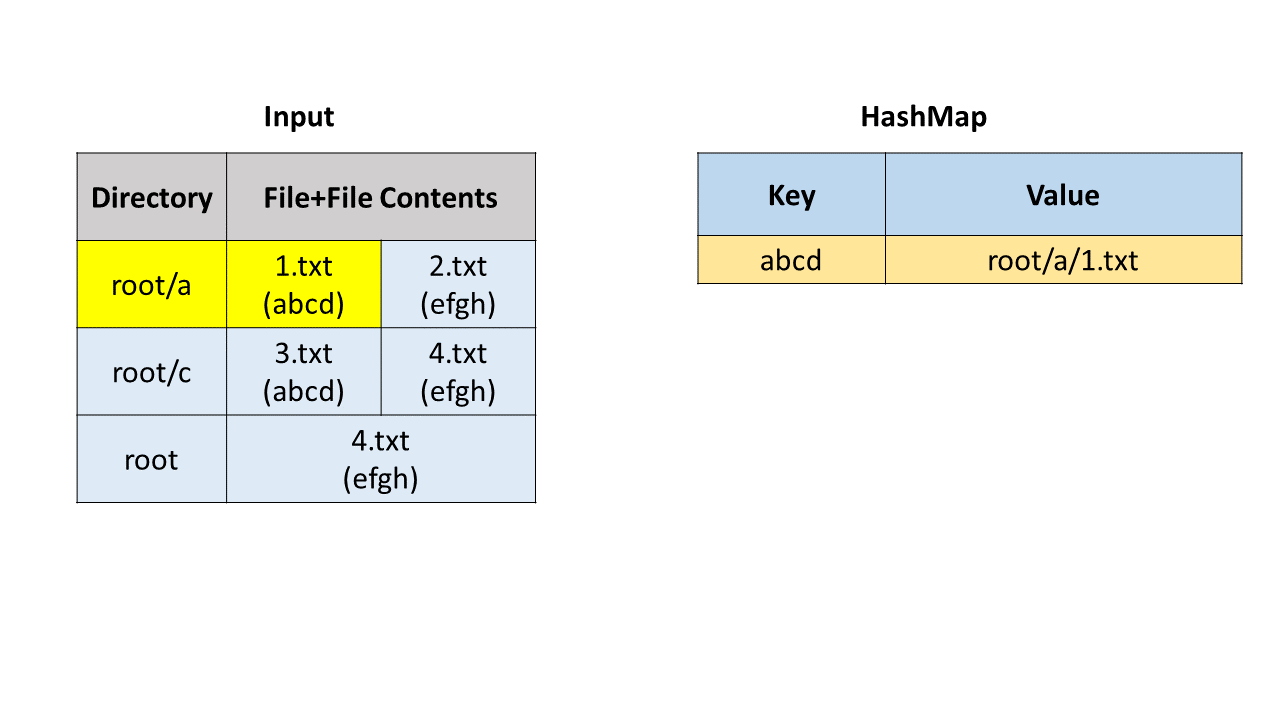
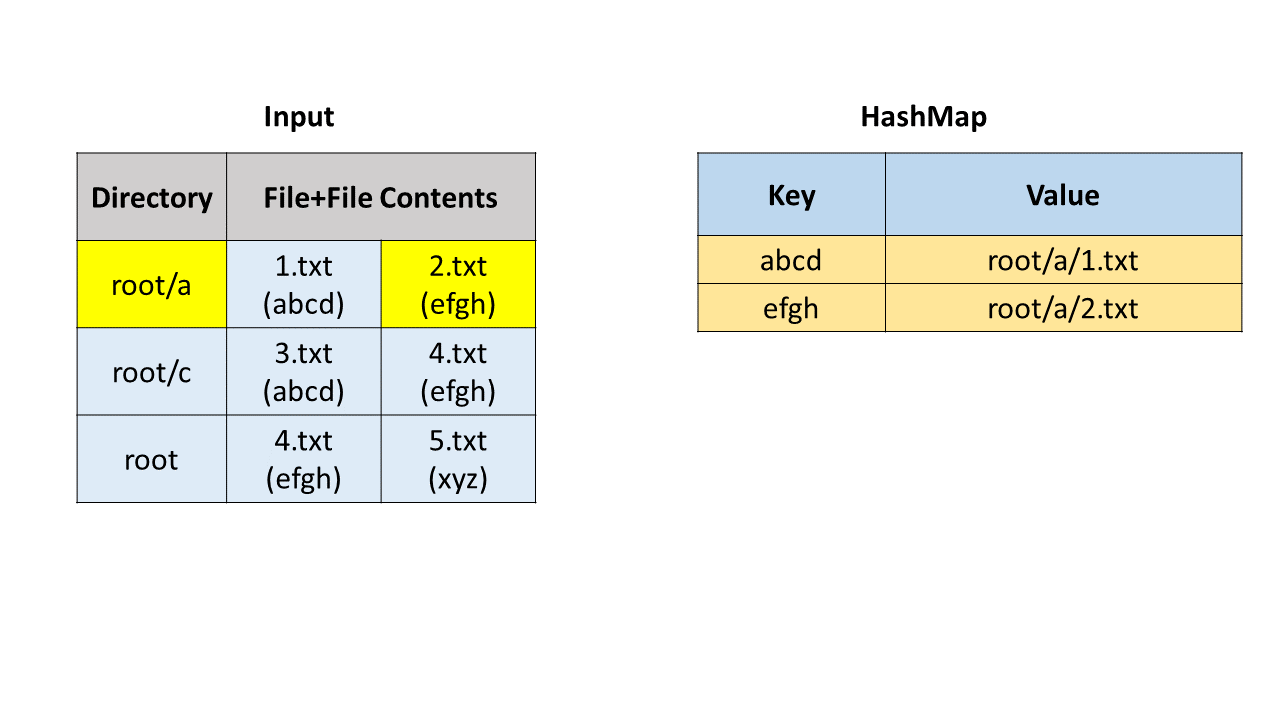
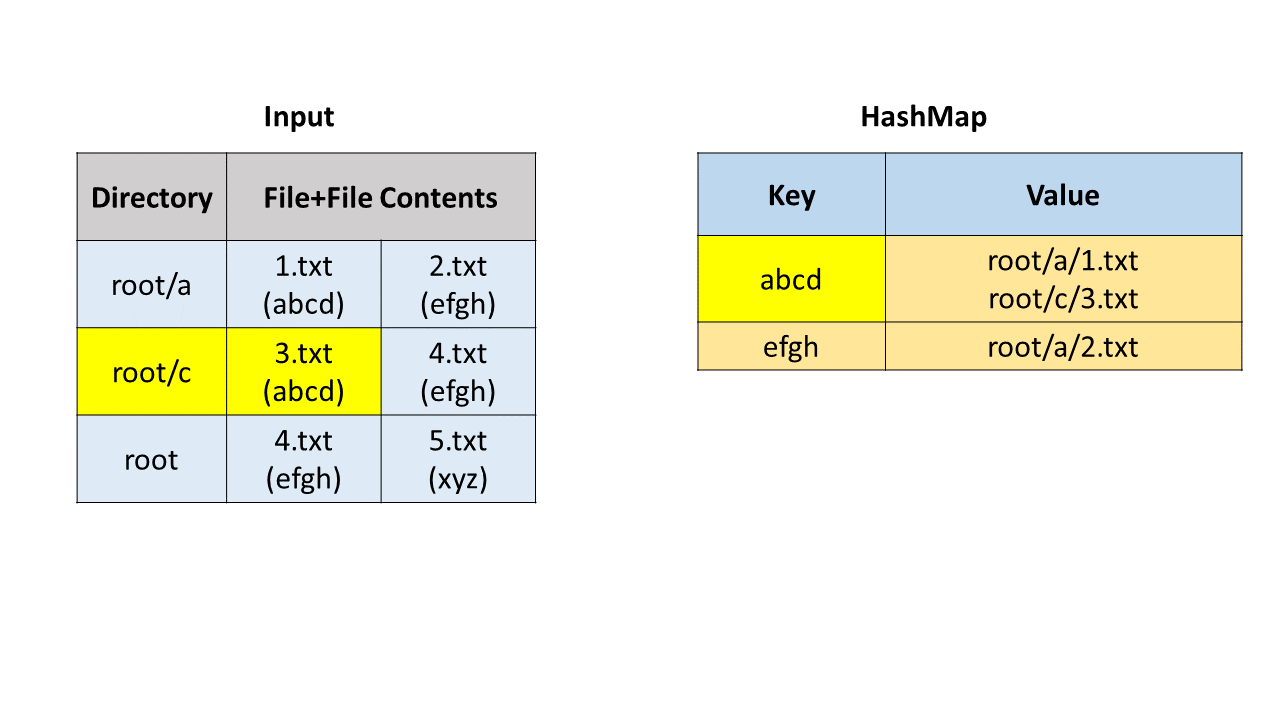
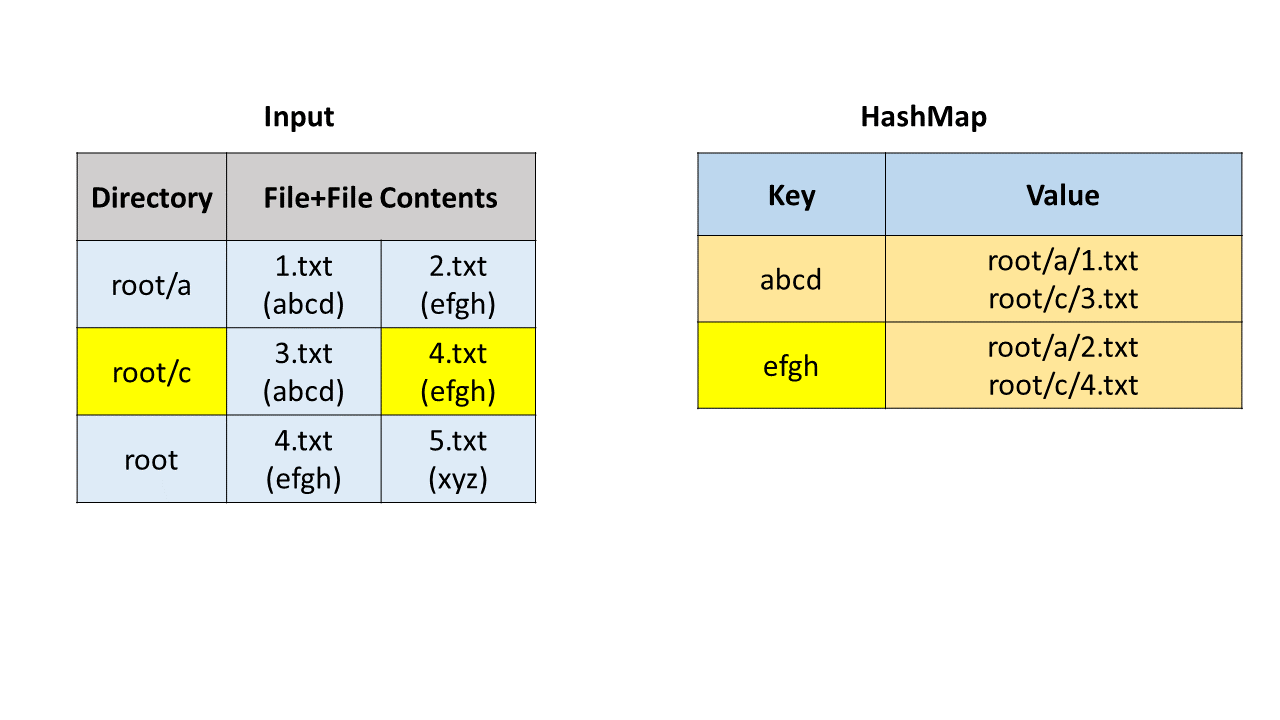
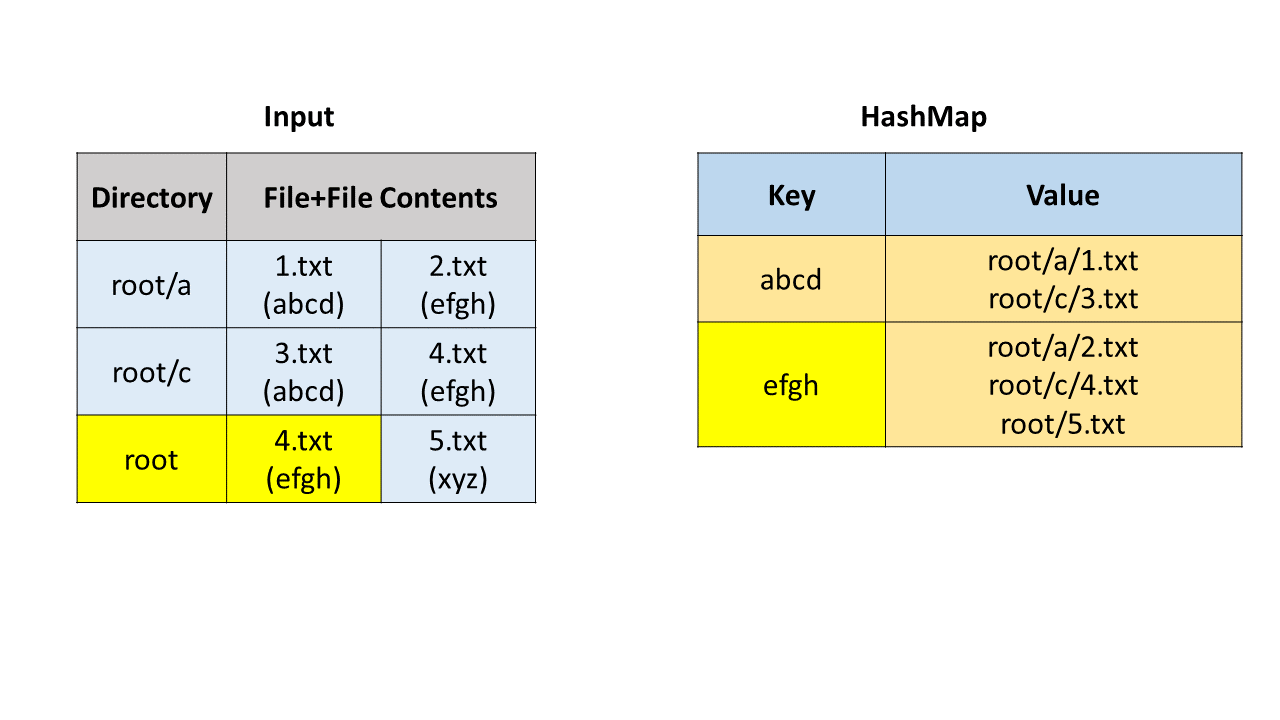
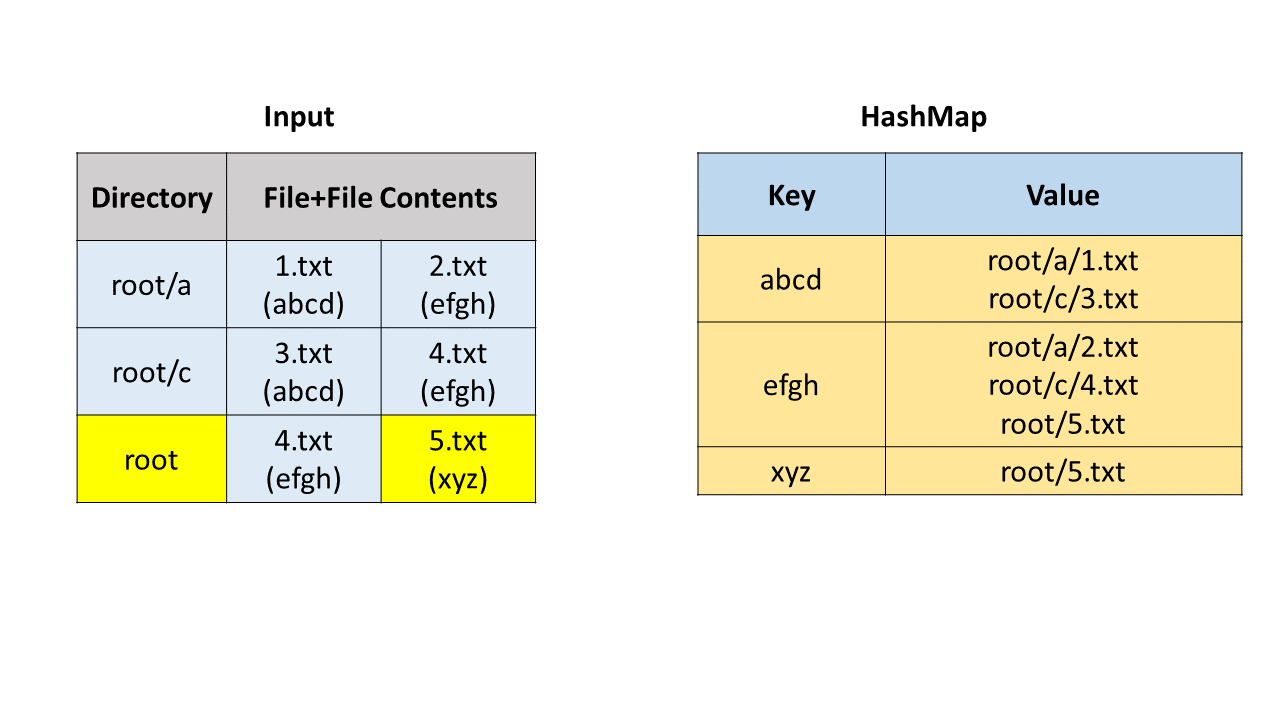
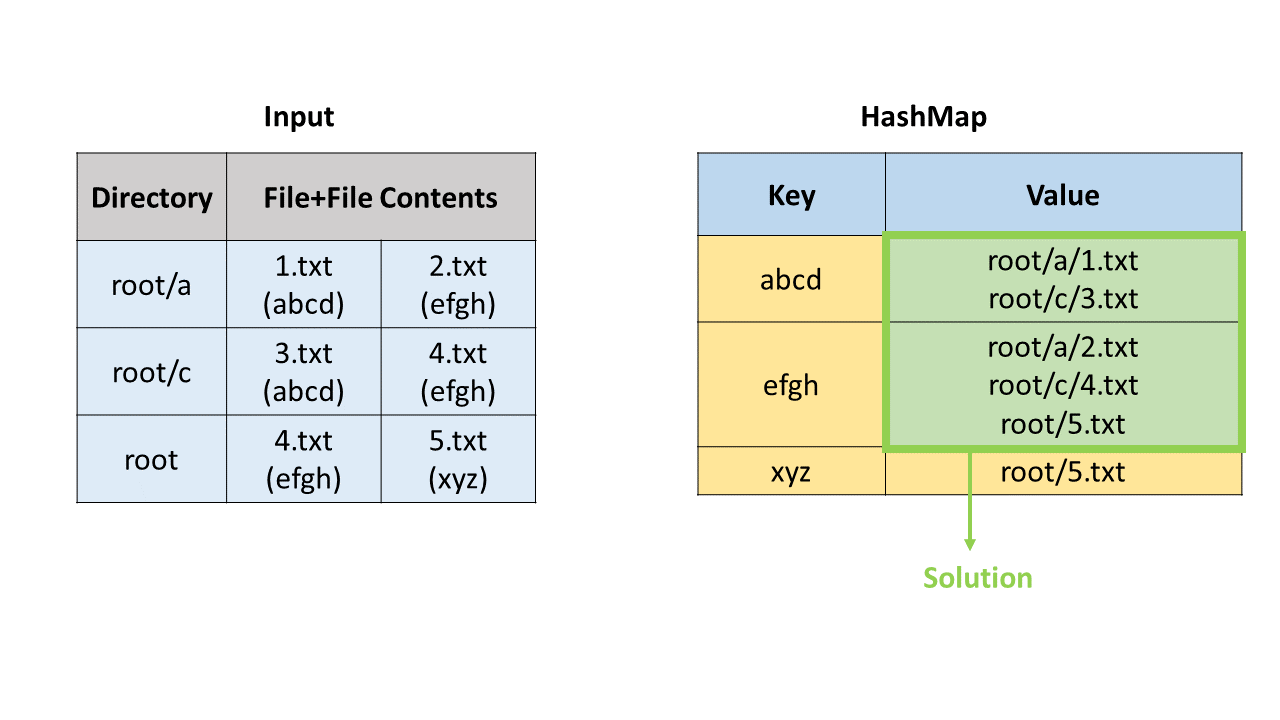
方法一:哈希表
首先我们通过字符串操作获取目录路径、文件名和文件内容。我们使用哈希映射(HashMap)来寻找重复文件,哈希映射中的键(key)是文件内容,值(value)是存储路径和文件名的列表。
我们遍历每一个文件,并把它加入哈希映射中。在这之后,我们遍历哈希映射,如果一个键对应的值列表的长度大于 1,说明我们找到了重复文件,可以把这个列表加入到答案中。
< ,
, ,
, ,
, ,
, ,
, ,
, ,
, >
>
1 | public class Solution { |
复杂度分析
时间复杂度:O(N),其中 N 是文件的总数。这里认为每个文件名的长度是常数级别的。
空间复杂度:O(N)。
Comments