长度相同的两个字符串 a 和 b 比较字典序大小,如果在 a 和 b 出现不同的第一个位置,a 中字符在字母表中的出现顺序位于 b 中相应字符之后,就认为字符串 a 按字典序比字符串 b 更大。例如,"abcd" 按字典序比 "abcc" 更大,因为两个字符串出现不同的第一个位置是第四个字符,而 d 在字母表中的出现顺序位于 c 之后。
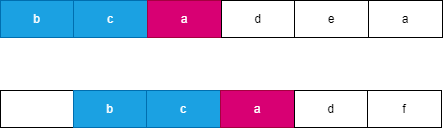
例如 word}_1 = \text{bcadea" 与 word}_2 = \text{_bcadf’’,此时 i = 0, j = 1, l = 4。
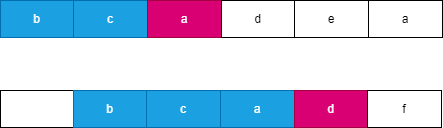
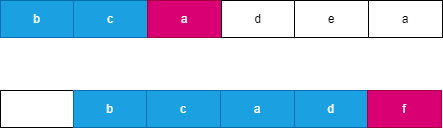
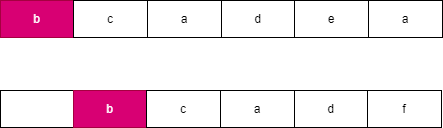
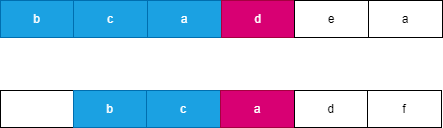
假设我们每次都选择从当前位置后缀较大的字符串,由于两个字符串分别从 i,j 开始连续 l 个字符相等,此时可以知道 word}_2 向右移动了 l 个位置到达了 j + l,此时 word}_1 向右移动了 t 个位置到达了 i + t,此时一定满足 t \le l,word}_2 优先向右移动到达字符 word}_2[j + l] 处,此时字典序较大的字符 word}_2[j + l] 优先进行合并。如果 word}_2 移动 k 个字符时,word}_1 最多也移动 k 个字符,由于两个字符串同时移动 k 个位置会遇到相同字符时总是选择字典序较大的后缀,因此 word}_2 一定先移动 l 个位置,可以参考如下图所示:
<,,,,,,>
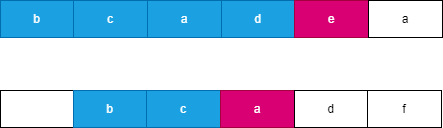
假设我们每次都选择从当前位置后缀较小的字符串,由于两个字符串分别从 i,j 开始连续 l 个字符相等,此时可以知道 word}_1 向右移动了 l 个位置到达了 i + l,此时 word}_2 向右移动了 t 个位置到达了 j + t,此时一定满足 t \le l,word}_1 优先向右移动到达字符 word}_1[i + l] 处,此时字典序较小的字符 word}_1[i + k] 优先进行合并。如果 word}_1 移动 k 个字符时,word}_2 最多也移动 k 个字符,而每次同时移动 k 个位置遇到相同字符时总是选择字典序较小的后缀,因此 word}_1 一定先移动 l 个位置,可以参考如下图所示:
<,,,,,,>
我们观察到不论以何种方式进行合并,两个字符串一共移动了 l + t 个位置,此时字符串 merge 也合并了长度为 l + t 的字符串 s,不论以何种方式进行合并的字符串 s 总是相同的,而此时下一个字符优先选择字典序较大的字符进行合并这样保证合并后的字典序最大。我们可以观察到上述示例中的 s = \text{``bcbcad’’。
classSolution: deflargestMerge(self, word1: str, word2: str) -> str: merge = [] i, j, n, m = 0, 0, len(word1), len(word2) while i < n or j < m: if i < n and word1[i:] > word2[j:]: merge.append(word1[i]) i += 1 else: merge.append(word2[j]) j += 1 return''.join(merge)
[sol1-C++]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution { public: string largestMerge(string word1, string word2){ string merge; int i = 0, j = 0; while (i < word1.size() || j < word2.size()) { if (i < word1.size() && word1.substr(i) > word2.substr(j)) { merge.push_back(word1[i++]); } else { merge.push_back(word2[j++]); } } return merge; } };
[sol1-Java]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution { public String largestMerge(String word1, String word2) { StringBuildermerge=newStringBuilder(); inti=0, j = 0; while (i < word1.length() || j < word2.length()) { if (i < word1.length() && word1.substring(i).compareTo(word2.substring(j)) > 0) { merge.append(word1.charAt(i)); i++; } else { merge.append(word2.charAt(j)); j++; } } return merge.toString(); } }
[sol1-C#]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
publicclassSolution { publicstringLargestMerge(string word1, string word2) { StringBuilder merge = new StringBuilder(); int i = 0, j = 0; while (i < word1.Length || j < word2.Length) { if (i < word1.Length && word1.Substring(i).CompareTo(word2.Substring(j)) > 0) { merge.Append(word1[i]); i++; } else { merge.Append(word2[j]); j++; } } return merge.ToString(); } }
[sol1-C]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
char * largestMerge(char * word1, char * word2) { int m = strlen(word1), n = strlen(word2); char *merge = (char *)malloc(sizeof(char) * (m + n + 1)); int i = 0, j = 0, pos = 0; while (i < m || j < n) { if (i < m && strcmp(word1 + i, word2 + j) > 0) { merge[pos] = word1[i]; pos++, i++; } else { merge[pos] = word2[j]; pos++, j++; } } merge[pos] = '\0'; return merge; }
[sol1-JavaScript]
1 2 3 4 5 6 7 8 9 10 11 12 13 14
var largestMerge = function(word1, word2) { let merge = ''; let i = 0, j = 0; while (i < word1.length || j < word2.length) { if (i < word1.length && word1.slice(i) > word2.slice(j)) { merge += word1[i]; i++; } else { merge += word2[j]; j++; } } return merge; };
[sol1-Golang]
1 2 3 4 5 6 7 8 9 10 11 12 13 14
funclargestMerge(word1, word2 string)string { merge := []byte{} i, j, n, m := 0, 0, len(word1), len(word2) for i < n || j < m { if i < n && word1[i:] > word2[j:] { merge = append(merge, word1[i]) i += 1 } else { merge = append(merge, word2[j]) j += 1 } } returnstring(merge) }
复杂度分析
时间复杂度:O((m + n) \times \max(m, n)),其中 m,n 分别表示两个字符串的长度。每次压入字符时需要进行后缀比较,每次两个字符串后缀比较的时间复杂度为 O(\max(m, n)),一共最多需要比较 m + n 次,因此总的时间复杂度为 O((m + n) \times \max(m, n))。
vector<int> sortCharacters(const string & text){ int n = text.size(); vector<int> count(128), order(n); for (auto c : text) { count[c]++; } for (int i = 1; i < 128; i++) { count[i] += count[i - 1]; } for (int i = n - 1; i >= 0; i--) { count[text[i]]--; order[count[text[i]]] = i; } return order; }
vector<int> computeCharClasses(const string & text, vector<int> & order){ int n = text.size(); vector<int> res(n, 0); res[order[0]] = 0; for (int i = 1; i < n; i++) { if (text[order[i]] != text[order[i - 1]]) { res[order[i]] = res[order[i - 1]] + 1; } else { res[order[i]] = res[order[i - 1]]; } } return res; }
vector<int> sortDoubled(const string & text, int len, vector<int> & order, vector<int> & classfiy){ int n = text.size(); vector<int> count(n), newOrder(n); for (int i = 0; i < n; i++) { count[classfiy[i]]++; } for (int i = 1; i < n; i++) { count[i] += count[i - 1]; } for (int i = n - 1; i >= 0; i--) { int start = (order[i] - len + n) % n; int cl = classfiy[start]; count[cl]--; newOrder[count[cl]] = start; } return newOrder; }
vector<int> updateClasses(vector<int> & newOrder, vector<int> & classfiy, int len){ int n = newOrder.size(); vector<int> newClassfiy(n, 0); newClassfiy[newOrder[0]] = 0; for (int i = 1; i < n; i++) { int curr = newOrder[i]; int prev = newOrder[i - 1]; int mid = curr + len; int midPrev = (prev + len) % n; if (classfiy[curr] != classfiy[prev] || classfiy[mid] != classfiy[midPrev]) { newClassfiy[curr] = newClassfiy[prev] + 1; } else { newClassfiy[curr] = newClassfiy[prev]; } } return newClassfiy; }
vector<int> buildSuffixArray(const string& text){ vector<int> order = sortCharacters(text); vector<int> classfiy = computeCharClasses(text, order); int len = 1; int n = text.size(); for (int i = 1; i < n; i <<= 1) { order = sortDoubled(text, i, order, classfiy); classfiy = updateClasses(order, classfiy, i); } return order; }
classSolution { public: string largestMerge(string word1, string word2){ int m = word1.size(), n = word2.size(); string str = word1 + "@" + word2 + "*"; vector<int> suffixArray = buildSuffixArray(str); vector<int> rank(m + n + 2); for (int i = 0; i < m + n + 2; i++) { rank[suffixArray[i]] = i; }
string merge; int i = 0, j = 0; while (i < m || j < n) { if (i < m && rank[i] > rank[m + 1 + j]) { merge.push_back(word1[i++]); } else { merge.push_back(word2[j++]); } } return merge; } };
publicclassSolution { publicstringLargestMerge(string word1, string word2) { int m = word1.Length, n = word2.Length; String str = word1 + "@" + word2 + "*"; int[] suffixArray = BuildSuffixArray(str); int[] rank = newint[m + n + 2]; for (int idx = 0; idx < m + n + 2; idx++) { rank[suffixArray[idx]] = idx; }
StringBuilder merge = new StringBuilder(); int i = 0, j = 0; while (i < m || j < n) { if (i < m && rank[i] > rank[m + 1 + j]) { merge.Append(word1[i]); i++; } else { merge.Append(word2[j]); j++; } } return merge.ToString(); }
publicint[] BuildSuffixArray(String text) { int[] order = CortCharacters(text); int[] classfiy = ComputeCharClasses(text, order); int len = 1; int n = text.Length; for (int i = 1; i < n; i <<= 1) { order = SortDoubled(text, i, order, classfiy); classfiy = UpdateClasses(order, classfiy, i); } return order; }
publicint[] CortCharacters(String text) { int n = text.Length; int[] count = newint[128]; int[] order = newint[n]; for (int i = 0; i < n; i++) { char c = text[i]; count[c]++; } for (int i = 1; i < 128; i++) { count[i] += count[i - 1]; } for (int i = n - 1; i >= 0; i--) { count[text[i]]--; order[count[text[i]]] = i; } return order; }
publicint[] ComputeCharClasses(String text, int[] order) { int n = text.Length; int[] res = newint[n]; res[order[0]] = 0; for (int i = 1; i < n; i++) { if (text[order[i]] != text[order[i - 1]]) { res[order[i]] = res[order[i - 1]] + 1; } else { res[order[i]] = res[order[i - 1]]; } } return res; }
publicint[] SortDoubled(String text, int len, int[] order, int[] classfiy) { int n = text.Length; int[] count = newint[n]; int[] newOrder = newint[n]; for (int i = 0; i < n; i++) { count[classfiy[i]]++; } for (int i = 1; i < n; i++) { count[i] += count[i - 1]; } for (int i = n - 1; i >= 0; i--) { int start = (order[i] - len + n) % n; int cl = classfiy[start]; count[cl]--; newOrder[count[cl]] = start; } return newOrder; }
publicint[] UpdateClasses(int[] newOrder, int[] classfiy, int len) { int n = newOrder.Length; int[] newClassfiy = newint[n]; newClassfiy[newOrder[0]] = 0; for (int i = 1; i < n; i++) { int curr = newOrder[i]; int prev = newOrder[i - 1]; int mid = curr + len; int midPrev = (prev + len) % n; if (classfiy[curr] != classfiy[prev] || classfiy[mid] != classfiy[midPrev]) { newClassfiy[curr] = newClassfiy[prev] + 1; } else { newClassfiy[curr] = newClassfiy[prev]; } } return newClassfiy; } }
voidsortCharacters(constchar *text, int *order) { int n = strlen(text); int count[128]; memset(count, 0, sizeof(count)); for (int i = 0; text[i] != '\0'; i++) { count[text[i]]++; } for (int i = 1; i < 128; i++) { count[i] += count[i - 1]; } for (int i = n - 1; i >= 0; i--) { count[text[i]]--; order[count[text[i]]] = i; } }
voidcomputeCharClasses(constchar *text, constint* order, int *classfiy) { int n = strlen(text); classfiy[order[0]] = 0; for (int i = 1; i < n; i++) { if (text[order[i]] != text[order[i - 1]]) { classfiy[order[i]] = classfiy[order[i - 1]] + 1; } else { classfiy[order[i]] = classfiy[order[i - 1]]; } } }
voidsortDoubled(constchar *text, int len, constint *order, constint *classfiy, int *newOrder) { int n = strlen(text); int count[n]; memset(count, 0, sizeof(count)); for (int i = 0; i < n; i++) { count[classfiy[i]]++; } for (int i = 1; i < n; i++) { count[i] += count[i - 1]; } for (int i = n - 1; i >= 0; i--) { int start = (order[i] - len + n) % n; int cl = classfiy[start]; count[cl]--; newOrder[count[cl]] = start; } }
voidupdateClasses(constint *newOrder, int n, int *classfiy, int len, int *newClassfiy) { newClassfiy[newOrder[0]] = 0; for (int i = 1; i < n; i++) { int curr = newOrder[i]; int prev = newOrder[i - 1]; int mid = curr + len; int midPrev = (prev + len) % n; if (classfiy[curr] != classfiy[prev] || classfiy[mid] != classfiy[midPrev]) { newClassfiy[curr] = newClassfiy[prev] + 1; } else { newClassfiy[curr] = newClassfiy[prev]; } } }
int *buildSuffixArray(constchar *text) { int n = strlen(text); int *order = (int *)malloc(sizeof(int) * n); int classfiy[n], newOrder[n], newClassfiy[n]; sortCharacters(text, order); computeCharClasses(text, order, classfiy); for (int i = 1; i < n; i <<= 1) { sortDoubled(text, i, order, classfiy, newOrder); updateClasses(newOrder, n, classfiy, i, newClassfiy); memcpy(order, newOrder, sizeof(int) * n); memcpy(classfiy, newClassfiy, sizeof(int) * n); } return order; }
char * largestMerge(char * word1, char * word2) { int m = strlen(word1), n = strlen(word2); char str[m + n + 3]; sprintf(str, "%s@%s*", word1, word2); int *suffixArray = buildSuffixArray(str); int rank[m + n + 2]; for (int i = 0; i < m + n + 2; i++) { rank[suffixArray[i]] = i; } free(suffixArray);
char *merge = (char *)malloc(sizeof(char) * (m + n + 1)); int i = 0, j = 0, pos = 0; while (i < m || j < n) { if (i < m && rank[i] > rank[m + 1 + j]) { merge[pos] = word1[i]; pos++, i++; } else { merge[pos] = word2[j]; pos++, j++; } } merge[pos] = '\0'; return merge; }
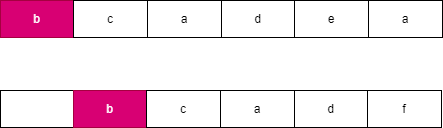 ,
,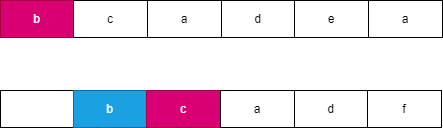 ,
,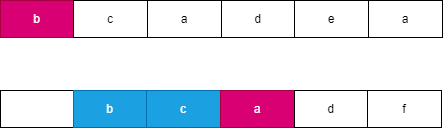 ,
,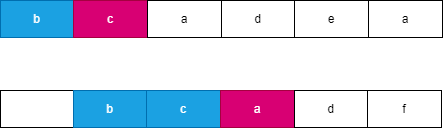 ,
, ,
, ,
, >
> ,
,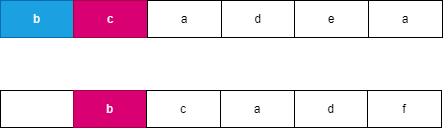 ,
,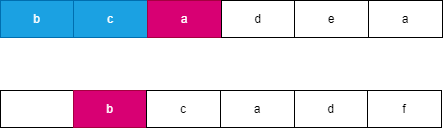 ,
,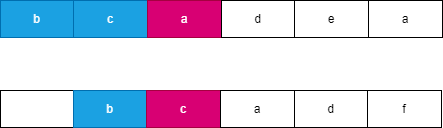 ,
,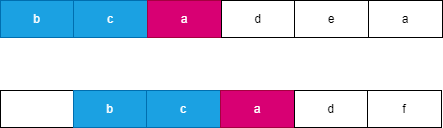 ,
, ,
, >
>