序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 /
提示: 输入输出格式与 LeetCode 目前使用的方式一致,详情请参阅 [LeetCode 序列化二叉树的格式](/faq/#binary-
示例 1:
**输入:** root = [1,2,3,null,null,4,5]
**输出:** [1,2,3,null,null,4,5]
示例 2:
**输入:** root = []
**输出:** []
示例 3:
**输入:** root = [1]
**输出:** [1]
示例 4:
**输入:** root = [1,2]
**输出:** [1,2]
提示:
树中结点数在范围 [0, 104] 内
-1000 <= Node.val <= 1000
方法一:深度优先搜索 思路和算法
二叉树的序列化本质上是对其值进行编码,更重要的是对其结构进行编码。可以遍历树来完成上述任务。众所周知,我们一般有两个策略:广度优先搜索和深度优先搜索。
广度优先搜索可以按照层次的顺序从上到下遍历所有的节点
深度优先搜索可以从一个根开始,一直延伸到某个叶,然后回到根,到达另一个分支。根据根节点、左节点和右节点之间的相对顺序,可以进一步将深度优先搜索策略区分为:
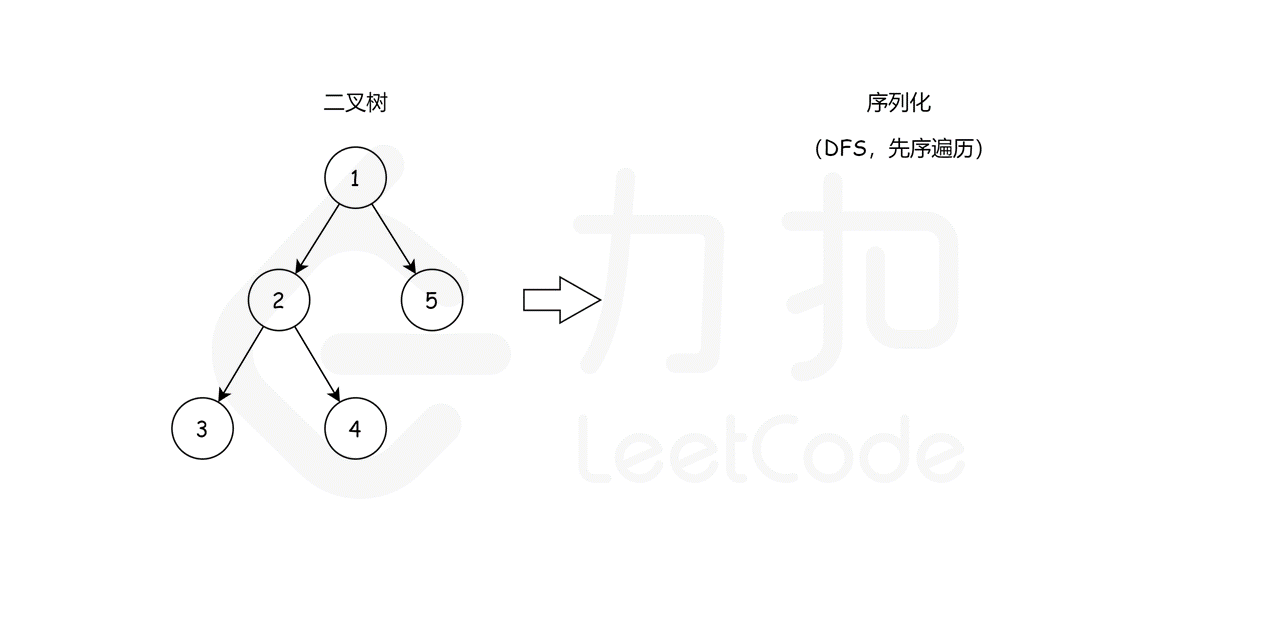
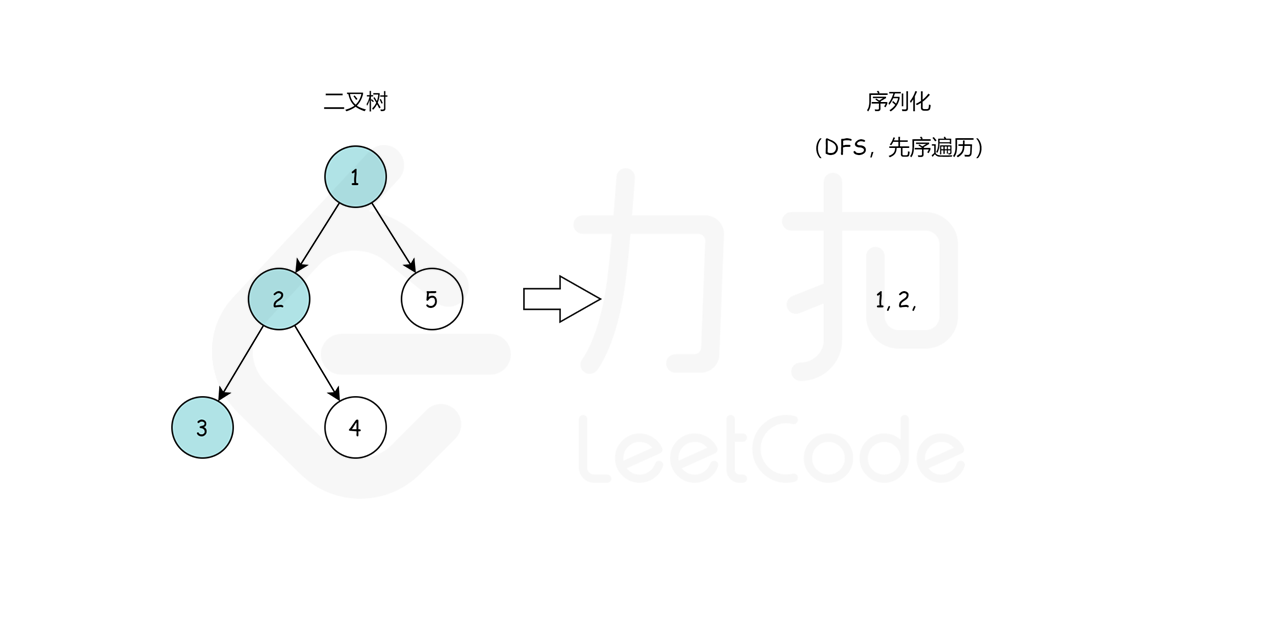
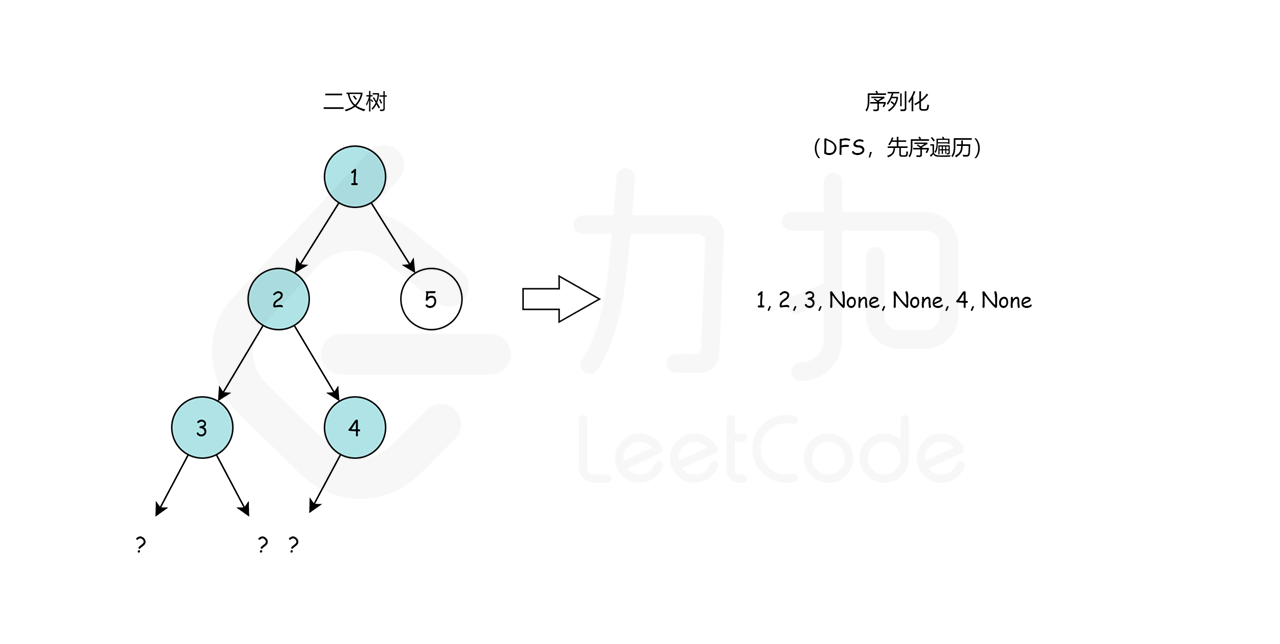
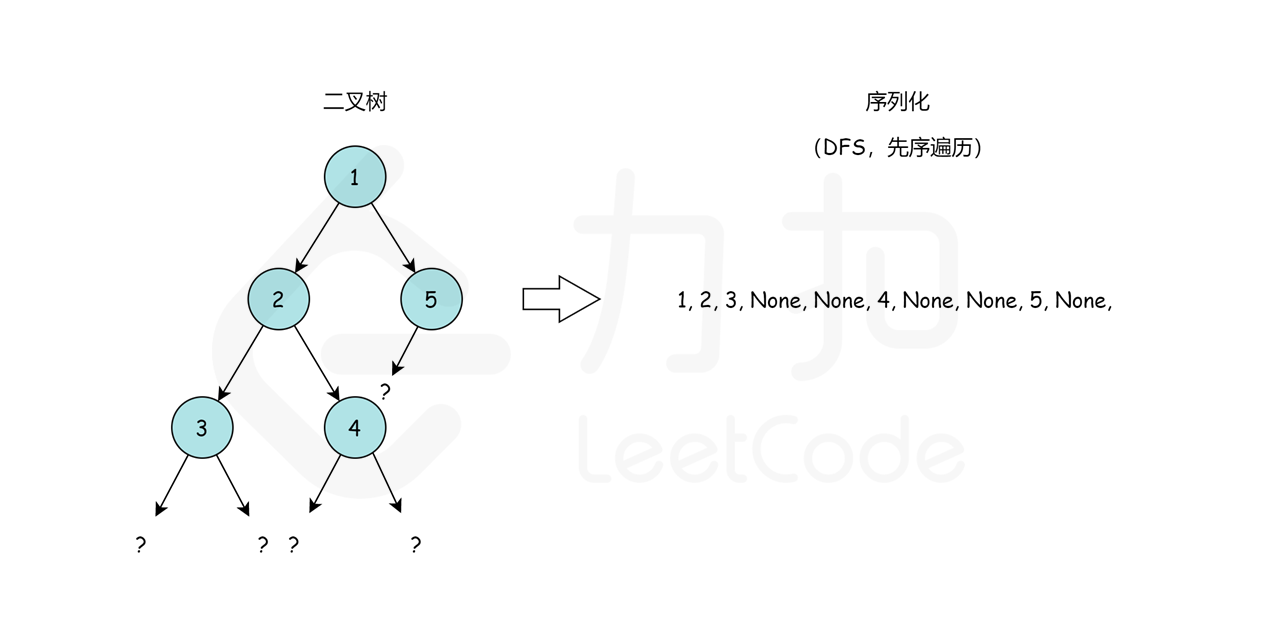
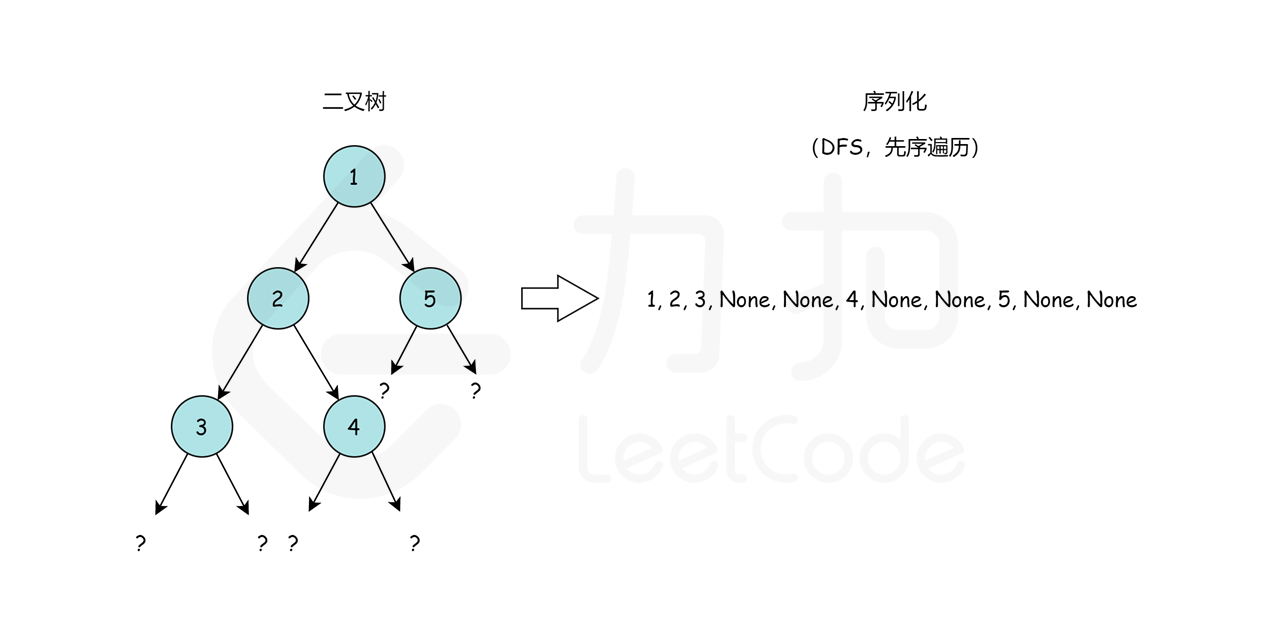
这里,我们选择先序遍历的编码方式,我们可以通过这样一个例子简单理解:
<
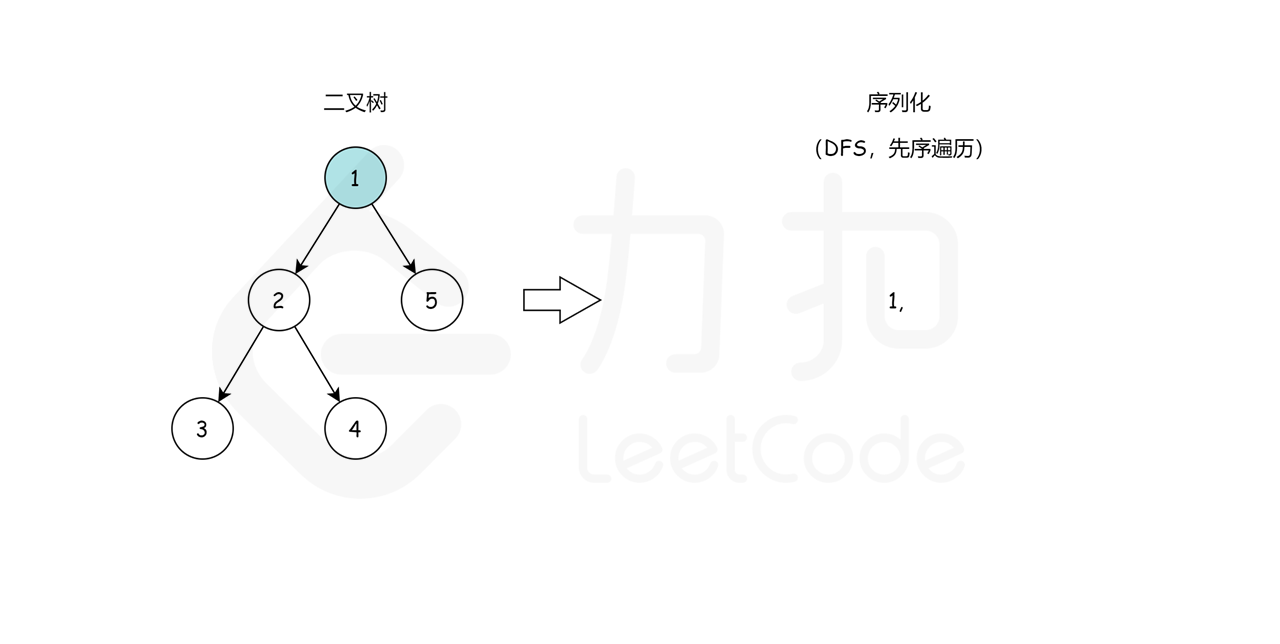
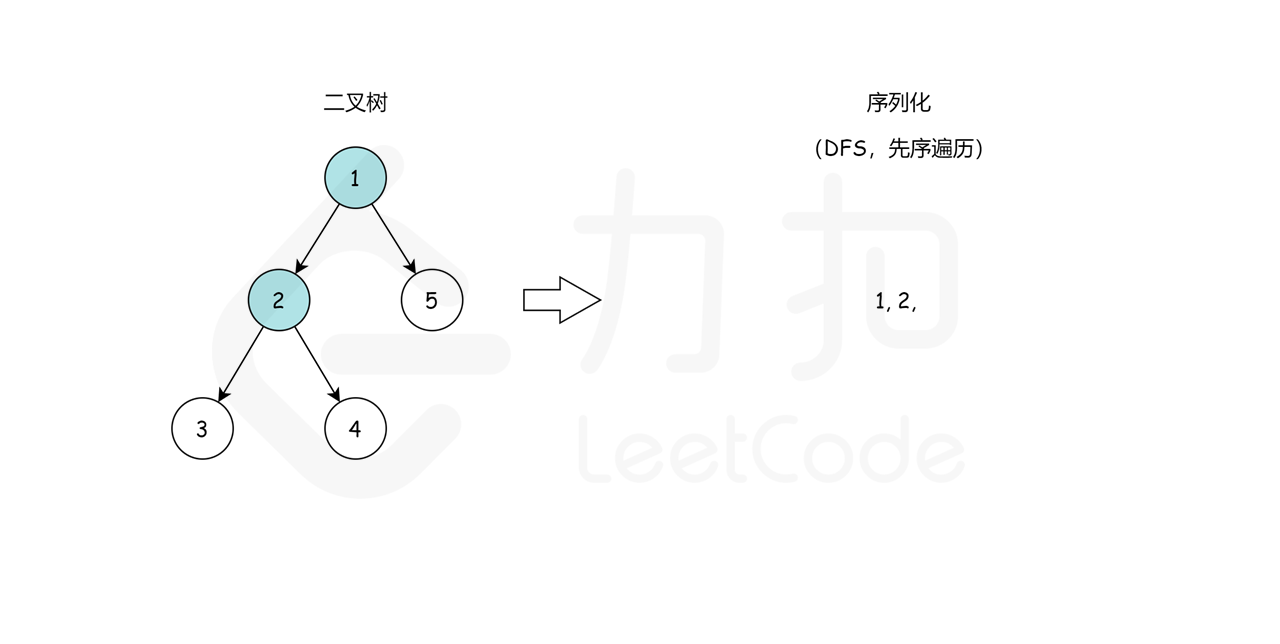
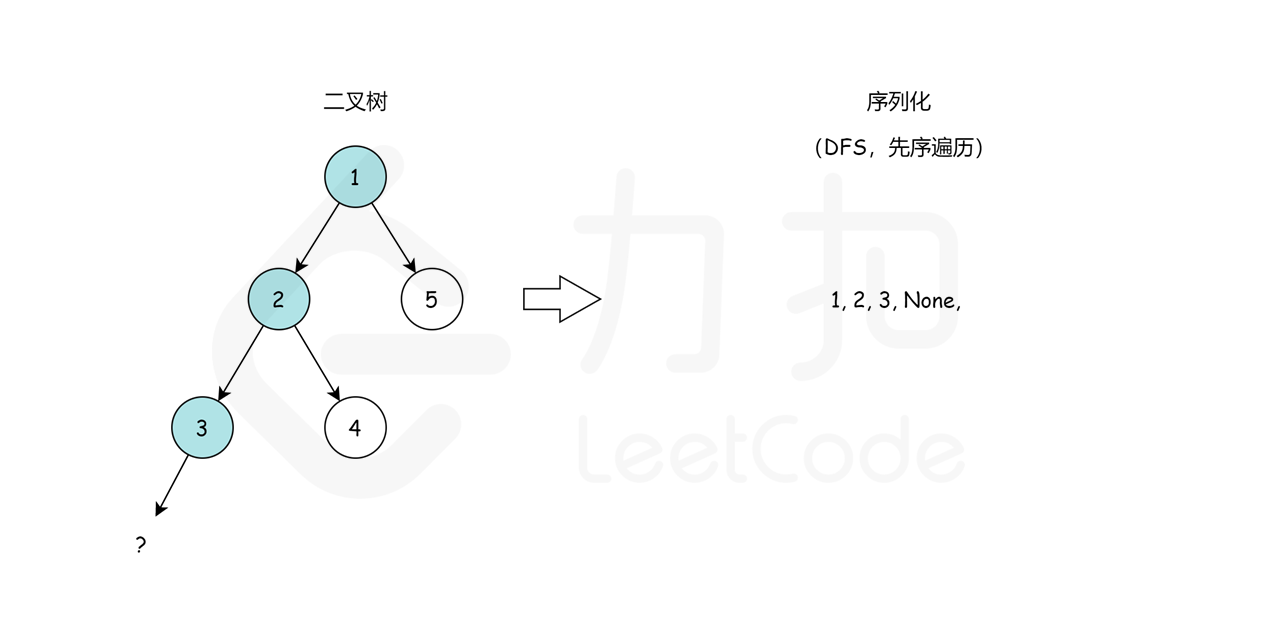
我们从根节点 1 开始,序列化字符串是 1,。然后我们跳到根节点 2 的左子树,序列化字符串变成 1,2,。现在从节点 2 开始,我们访问它的左节点 3(1,2,3,None,None,)和右节点 4
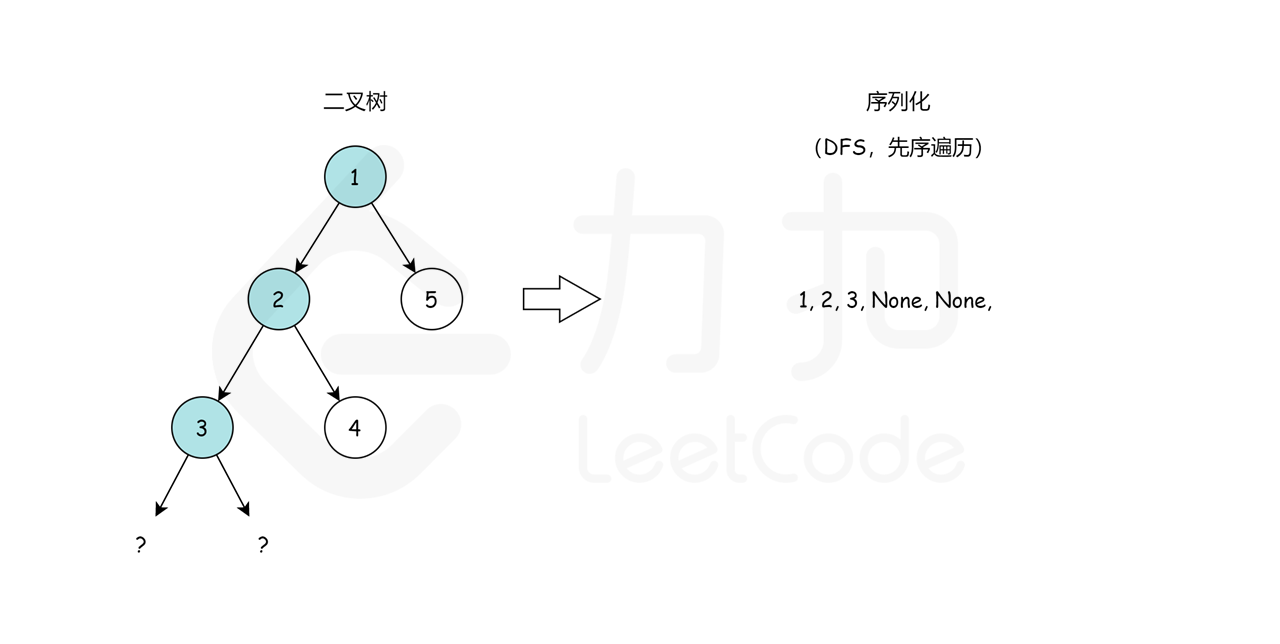
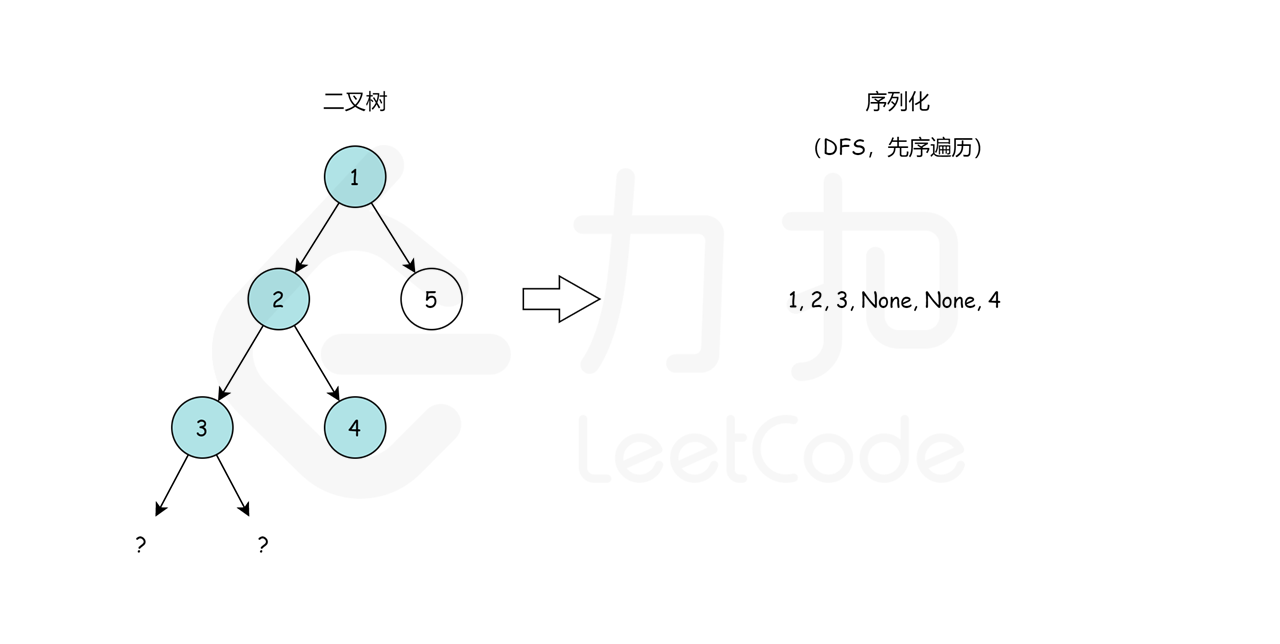
(1,2,3,None,None,4,None,None)。None,None, 是用来标记缺少左、右子节点,这就是我们在序列化期间保存树结构的方式。最后,我们回到根节点 1 并访问它的右子树,它恰好是叶节点 5。最后,序列化字符串是 1,2,3,None,None,4,None,None,5,None,None,。
即我们可以先序遍历这颗二叉树,遇到空子树的时候序列化成 None,否则继续递归序列化。那么我们如何反序列化呢?首先我们需要根据 , 把原先的序列分割开来得到先序遍历的元素列表,然后从左向右遍历这个序列:
如果当前的元素为 None,则当前为空树
否则先解析这棵树的左子树,再解析它的右子树
具体请参考下面的代码。
代码
[sol1-Java] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class Codec { public String serialize (TreeNode root) { return rserialize(root, "" ); } public TreeNode deserialize (String data) { String[] dataArray = data.split("," ); List<String> dataList = new LinkedList <String>(Arrays.asList(dataArray)); return rdeserialize(dataList); } public String rserialize (TreeNode root, String str) { if (root == null ) { str += "None," ; } else { str += str.valueOf(root.val) + "," ; str = rserialize(root.left, str); str = rserialize(root.right, str); } return str; } public TreeNode rdeserialize (List<String> dataList) { if (dataList.get(0 ).equals("None" )) { dataList.remove(0 ); return null ; } TreeNode root = new TreeNode (Integer.valueOf(dataList.get(0 ))); dataList.remove(0 ); root.left = rdeserialize(dataList); root.right = rdeserialize(dataList); return root; } }
[sol1-C#] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class Codec { public string serialize (TreeNode root ) return rserialize(root, "" ); } public TreeNode deserialize (string data string [] dataArray = data.Split("," ); LinkedList<string > dataList = new LinkedList<string >(dataArray.ToList()); return rdeserialize(dataList); } public string rserialize (TreeNode root, string str ) if (root == null ) { str += "None," ; } else { str += root.val.ToString() + "," ; str = rserialize(root.left, str); str = rserialize(root.right, str); } return str; } public TreeNode rdeserialize (LinkedList<string > dataList ) if (dataList.First.Value.Equals("None" )) { dataList.RemoveFirst(); return null ; } TreeNode root = new TreeNode(int .Parse(dataList.First.Value)); dataList.RemoveFirst(); root.left = rdeserialize(dataList); root.right = rdeserialize(dataList); return root; } }
[sol1-C++] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class Codec {public : void rserialize (TreeNode* root, string& str) if (root == nullptr ) { str += "None," ; } else { str += to_string (root->val) + "," ; rserialize (root->left, str); rserialize (root->right, str); } } string serialize (TreeNode* root) { string ret; rserialize (root, ret); return ret; } TreeNode* rdeserialize (list<string>& dataArray) { if (dataArray.front () == "None" ) { dataArray.erase (dataArray.begin ()); return nullptr ; } TreeNode* root = new TreeNode (stoi (dataArray.front ())); dataArray.erase (dataArray.begin ()); root->left = rdeserialize (dataArray); root->right = rdeserialize (dataArray); return root; } TreeNode* deserialize (string data) { list<string> dataArray; string str; for (auto & ch : data) { if (ch == ',' ) { dataArray.push_back (str); str.clear (); } else { str.push_back (ch); } } if (!str.empty ()) { dataArray.push_back (str); str.clear (); } return rdeserialize (dataArray); } };
[sol1-JavaScript] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 var serialize = function (root ) { return rserialize (root, '' ); }; var deserialize = function (data ) { const dataArray = data.split ("," ); return rdeserialize (dataArray); }; const rserialize = (root, str ) => { if (root === null ) { str += "None," ; } else { str += root.val + '' + "," ; str = rserialize (root.left , str); str = rserialize (root.right , str); } return str; } const rdeserialize = (dataList ) => { if (dataList[0 ] === "None" ) { dataList.shift (); return null ; } const root = new TreeNode (parseInt (dataList[0 ])); dataList.shift (); root.left = rdeserialize (dataList); root.right = rdeserialize (dataList); return root; }
[sol1-Golang] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 type Codec struct {}func Constructor () return } func (Codec) string { sb := &strings.Builder{} var dfs func (*TreeNode) dfs = func (node *TreeNode) if node == nil { sb.WriteString("null," ) return } sb.WriteString(strconv.Itoa(node.Val)) sb.WriteByte(',' ) dfs(node.Left) dfs(node.Right) } dfs(root) return sb.String() } func (Codec) string ) *TreeNode { sp := strings.Split(data, "," ) var build func () build = func () if sp[0 ] == "null" { sp = sp[1 :] return nil } val, _ := strconv.Atoi(sp[0 ]) sp = sp[1 :] return &TreeNode{val, build(), build()} } return build() }
复杂度分析
时间复杂度:在序列化和反序列化函数中,我们只访问每个节点一次,因此时间复杂度为 $O(n)$,其中 $n$ 是节点数,即树的大小。
空间复杂度:在序列化和反序列化函数中,我们递归会使用栈空间,故渐进空间复杂度为 $O(n)$。
方法二:括号表示编码 + 递归下降解码 思路和算法
我们也可以这样表示一颗二叉树:
如果当前的树为空,则表示为 X
如果当前的树不为空,则表示为 (<LEFT_SUB_TREE>)CUR_NUM(RIGHT_SUB_TREE),其中:
<LEFT_SUB_TREE> 是左子树序列化之后的结果<RIGHT_SUB_TREE> 是右子树序列化之后的结果CUR_NUM 是当前节点的值
根据这样的定义,我们很好写出序列化的过程,后序遍历这颗二叉树即可,那如何反序列化呢?根据定义,我们可以推导出这样的巴科斯范式(BNF):
它的意义是:用 T 代表一棵树序列化之后的结果,| 表示 T 的构成为 (T) num (T) 或者 X,| 左边是对 T 的递归定义,右边规定了递归终止的边界条件。
因为:
T 的定义中,序列中的第一个字符要么是 X,要么是 (,所以这个定义是不含左递归的当我们开始解析一个字符串的时候,如果开头是 X,我们就知道这一定是解析一个「空树」的结构,如果开头是 (,我们就知道需要解析 (T) num (T) 的结构,因此这里两种开头和两种解析方法一一对应,可以确定这是一个无二义性的文法
我们只需要通过开头的第一个字母是 X 还是 ( 来判断使用哪一种解析方法
所以这个文法是 LL(1) 型文法,如果你不知道什么是 LL(1) 型文法也没有关系,你只需要知道它定义了一种递归的方法来反序列化,也保证了这个方法的正确性——我们可以设计一个递归函数:
这个递归函数传入两个参数,带解析的字符串和当前当解析的位置 ptr,ptr 之前的位置是已经解析的,ptr 和 ptr 后面的字符串是待解析的
如果当前位置为 X 说明解析到了一棵空树,直接返回
否则当前位置一定是 (,对括号内部按照 (T) num (T) 的模式解析
具体请参考下面的代码。
代码
[sol2-Java] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public class Codec { public String serialize (TreeNode root) { if (root == null ) { return "X" ; } String left = "(" + serialize(root.left) + ")" ; String right = "(" + serialize(root.right) + ")" ; return left + root.val + right; } public TreeNode deserialize (String data) { int [] ptr = {0 }; return parse(data, ptr); } public TreeNode parse (String data, int [] ptr) { if (data.charAt(ptr[0 ]) == 'X' ) { ++ptr[0 ]; return null ; } TreeNode cur = new TreeNode (0 ); cur.left = parseSubtree(data, ptr); cur.val = parseInt(data, ptr); cur.right = parseSubtree(data, ptr); return cur; } public TreeNode parseSubtree (String data, int [] ptr) { ++ptr[0 ]; TreeNode subtree = parse(data, ptr); ++ptr[0 ]; return subtree; } public int parseInt (String data, int [] ptr) { int x = 0 , sgn = 1 ; if (!Character.isDigit(data.charAt(ptr[0 ]))) { sgn = -1 ; ++ptr[0 ]; } while (Character.isDigit(data.charAt(ptr[0 ]))) { x = x * 10 + data.charAt(ptr[0 ]++) - '0' ; } return x * sgn; } }
[sol2-C#] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public class Codec { public string serialize (TreeNode root ) if (root == null ) { return "X" ; } string left = "(" + serialize(root.left) + ")" ; string right = "(" + serialize(root.right) + ")" ; return left + root.val + right; } public TreeNode deserialize (string data int [] ptr = {0 }; return parse(data, ptr); } public TreeNode parse (string data, int [] ptr if (data[ptr[0 ]] == 'X' ) { ++ptr[0 ]; return null ; } TreeNode cur = new TreeNode(0 ); cur.left = parseSubtree(data, ptr); cur.val = parseInt(data, ptr); cur.right = parseSubtree(data, ptr); return cur; } public TreeNode parseSubtree (string data, int [] ptr ++ptr[0 ]; TreeNode subtree = parse(data, ptr); ++ptr[0 ]; return subtree; } public int parseInt (string data, int [] ptr int x = 0 , sgn = 1 ; if (!char .IsDigit(data[ptr[0 ]])) { sgn = -1 ; ++ptr[0 ]; } while (char .IsDigit(data[ptr[0 ]])) { x = x * 10 + data[ptr[0 ]++] - '0' ; } return x * sgn; } }
[sol2-C++] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class Codec {public : string serialize (TreeNode* root) { if (!root) { return "X" ; } auto left = "(" + serialize (root->left) + ")" ; auto right = "(" + serialize (root->right) + ")" ; return left + to_string (root->val) + right; } inline TreeNode* parseSubtree (const string &data, int &ptr) ++ptr; auto subtree = parse (data, ptr); ++ptr; return subtree; } inline int parseInt (const string &data, int &ptr) int x = 0 , sgn = 1 ; if (!isdigit (data[ptr])) { sgn = -1 ; ++ptr; } while (isdigit (data[ptr])) { x = x * 10 + data[ptr++] - '0' ; } return x * sgn; } TreeNode* parse (const string &data, int &ptr) { if (data[ptr] == 'X' ) { ++ptr; return nullptr ; } auto cur = new TreeNode (0 ); cur->left = parseSubtree (data, ptr); cur->val = parseInt (data, ptr); cur->right = parseSubtree (data, ptr); return cur; } TreeNode* deserialize (string data) { int ptr = 0 ; return parse (data, ptr); } };
[sol2-JavaScript] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 var serialize = function (root ) { if (root == null ) { return "X" ; } const left = "(" + serialize (root.left ) + ")" ; const right = "(" + serialize (root.right ) + ")" ; return left + root.val + right; }; var deserialize = function (data ) { const ptr = [0 ]; return parse (data, ptr); }; const parse = (data, ptr ) => { if (data[ptr[0 ]] === 'X' ) { ++ptr[0 ]; return null ; } let cur = new TreeNode (0 ); cur.left = parseSubtree (data, ptr); cur.val = parseInt (data, ptr); cur.right = parseSubtree (data, ptr); return cur; } const parseSubtree = (data, ptr ) => { ++ptr[0 ]; const subtree = parse (data, ptr); ++ptr[0 ]; return subtree; } const parseInt = (data, ptr ) => { let x = 0 , sgn = 1 ; if (isNaN (Number (data[ptr[0 ]]))) { sgn = -1 ; ++ptr[0 ]; } while (!isNaN (Number (data[ptr[0 ]]))) { x = x * 10 + data[ptr[0 ]++].charCodeAt () - '0' .charCodeAt (); } return x * sgn; }
[sol2-Golang] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 type Codec struct {}func Constructor () return } func (c Codec) string { if root == nil { return "X" } left := "(" + c.serialize(root.Left) + ")" right := "(" + c.serialize(root.Right) + ")" return left + strconv.Itoa(root.Val) + right } func (Codec) string ) *TreeNode { var parse func () parse = func () if data[0 ] == 'X' { data = data[1 :] return nil } node := &TreeNode{} data = data[1 :] node.Left = parse() data = data[1 :] i := 0 for data[i] == '-' || '0' <= data[i] && data[i] <= '9' { i++ } node.Val, _ = strconv.Atoi(data[:i]) data = data[i:] data = data[1 :] node.Right = parse() data = data[1 :] return node } return parse() }
复杂度分析
时间复杂度:序列化时做了一次遍历,渐进时间复杂度为 $O(n)$。反序列化时,在解析字符串的时候 ptr 指针对字符串做了一次顺序遍历,字符串长度为 $O(n)$,故这里的渐进时间复杂度为 $O(n)$。
空间复杂度:考虑递归使用的栈空间的大小,这里栈空间的使用和递归深度有关,递归深度又和二叉树的深度有关,在最差情况下,二叉树退化成一条链,故这里的渐进空间复杂度为 $O(n)$。
 ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, >
>