0399-除法求值
给你一个变量对数组 equations 和一个实数值数组 values 作为已知条件,其中 equations[i] = [Ai, Bi] 和values[i] 共同表示等式 Ai / Bi = values[i] 。每个 Ai 或 Bi 是一个表示单个变量的字符串。
另有一些以数组 queries 表示的问题,其中 queries[j] = [Cj, Dj] 表示第 j 个问题,请你根据已知条件找出 Cj / Dj = ? 的结果作为答案。
返回 所有问题的答案 。如果存在某个无法确定的答案,则用 -1.0 替代这个答案。如果问题中出现了给定的已知条件中没有出现的字符串,也需要用-1.0 替代这个答案。
注意: 输入总是有效的。你可以假设除法运算中不会出现除数为 0 的情况,且不存在任何矛盾的结果。
注意: 未在等式列表中出现的变量是未定义的,因此无法确定它们的答案。
示例 1:
**输入:** equations = [["a","b"],["b","c"]], values = [2.0,3.0], queries = [["a","c"],["b","a"],["a","e"],["a","a"],["x","x"]]
**输出:** [6.00000,0.50000,-1.00000,1.00000,-1.00000]
**解释:**
条件: _a / b = 2.0_ , _b / c = 3.0_
问题: _a / c = ?_ , _b / a = ?_ , _a / e = ?_ , _a / a = ?_ , _x / x = ?_
结果:[6.0, 0.5, -1.0, 1.0, -1.0 ]
注意:x 是未定义的 => -1.0
示例 2:
**输入:** equations = [["a","b"],["b","c"],["bc","cd"]], values = [1.5,2.5,5.0], queries = [["a","c"],["c","b"],["bc","cd"],["cd","bc"]]
**输出:** [3.75000,0.40000,5.00000,0.20000]
示例 3:
**输入:** equations = [["a","b"]], values = [0.5], queries = [["a","b"],["b","a"],["a","c"],["x","y"]]
**输出:** [0.50000,2.00000,-1.00000,-1.00000]
提示:
1 <= equations.length <= 20equations[i].length == 21 <= Ai.length, Bi.length <= 5values.length == equations.length0.0 < values[i] <= 20.01 <= queries.length <= 20queries[i].length == 21 <= Cj.length, Dj.length <= 5Ai, Bi, Cj, Dj由小写英文字母与数字组成
📺 视频讲解

📖 文字解析
这道题是在「力扣」第 990 题(等式方程的可满足性 )的基础上,在变量和变量之间有了倍数关系。由于 变量之间的倍数关系具有传递性,处理有传递性关系的问题,可以使用「并查集」,我们需要在并查集的「合并」与「查询」操作中 维护这些变量之间的倍数关系。
说明:请大家注意看一下题目中的「注意」和「数据范围」,例如:每个 Ai 或 Bi 是一个表示单个变量的字符串。所以用例 equation = ["ab", "cd"] ,这里的 ab 视为一个变量,不表示 a * b。如果面试中遇到这样的问题,一定要和面试官确认清楚题目的条件。还有 1 <= equations.length <= 20 和 values[i] > 0.0 可以避免一些特殊情况的讨论。
方法:并查集
分析示例 1:
a / b = 2.0说明 $a = 2b$,a和b在同一个集合中;b / c = 3.0说明 $b = 3c$ ,b和c在同一个集合中。
求 $\cfrac{a}{c ,可以把 $a = 2b$,$b = 3c$ 依次代入,得到 $\cfrac{a}{c} = \cfrac{2b} {c} = \cfrac{2 \cdot 3c} {c} = 6.0$;
求 $\cfrac{b}{a ,很显然根据 $a = 2b$,知道 $\cfrac{b}{a} = 0.5$,也可以把 $b$ 和 $a$ 都转换成为 $c$ 的倍数,$\cfrac{b}{a} = \cfrac{b} {2b} = \cfrac{3c} {6c} = \cfrac{1}{2} = 0.5$;
我们计算了两个结果,不难知道:可以将题目给出的 equation 中的两个变量所在的集合进行「合并」,同在一个集合中的两个变量就可以通过某种方式计算出它们的比值。具体来说,可以把 不同的变量的比值转换成为相同的变量的比值,这样在做除法的时候就可以消去相同的变量,然后再计算转换成相同变量以后的系数的比值,就是题目要求的结果。统一了比较的标准,可以以 $O(1)$ 的时间复杂度完成计算。
如果两个变量不在同一个集合中, 返回 $-1.0$。并且根据题目的意思,如果两个变量中 至少有一个 变量没有出现在所有 equations 出现的字符集合中,也返回 $-1.0$。
构建有向图
通过例 1 的分析,我们就知道了,题目给出的 equations 和 values 可以表示成一个图,equations 中出现的变量就是图的顶点,「分子」于「分母」的比值可以表示成一个有向关系(因为「分子」和「分母」是有序的,不可以对换),并且这个图是一个带权图,values 就是对应的有向边的权值。例 1 中给出的 equations 和 values 表示的「图形表示」、「数学表示」和「代码表示」如下表所示。其中 parent[a] = b 表示:结点 a 的(直接)父亲结点是 b,与之对应的有向边的权重,记为 weight[a] = 2.0,即 weight[a] 表示结点 a 到它的 直接父亲结点 的有向边的权重。
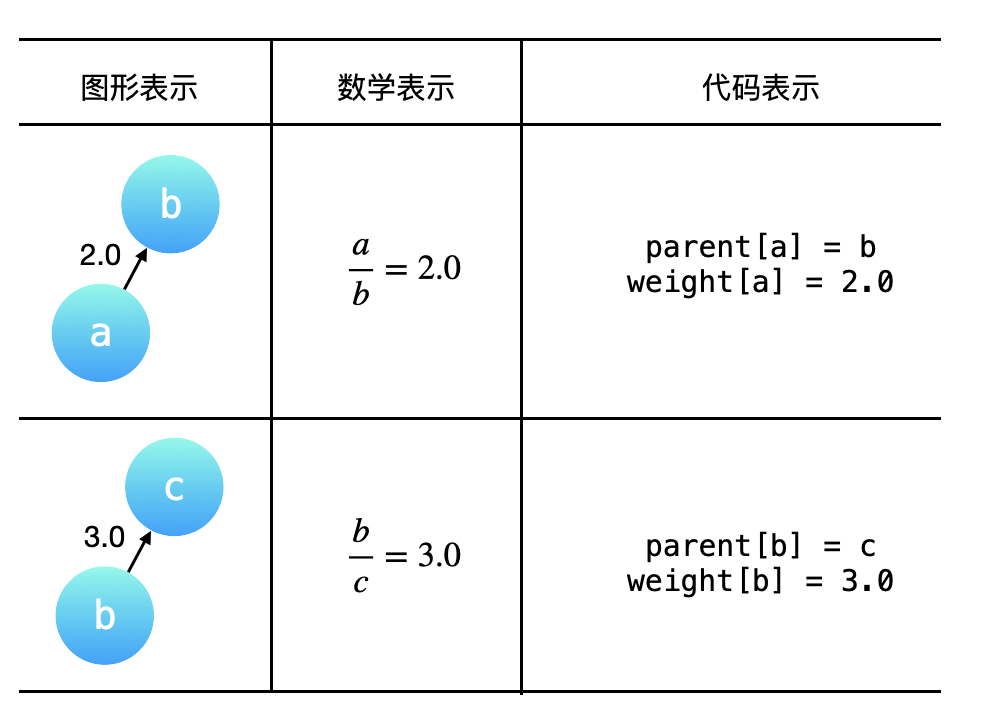 {:width=400}
{:width=400}
「统一变量」与「路径压缩」的关系
刚刚在分析例 1 的过程中,提到了:可以把一个一个 query 中的不同变量转换成 同一个变量,这样在计算 query 的时候就可以以 $O(1)$ 的时间复杂度计算出结果,在「并查集」的一个优化技巧中,「路径压缩」就恰好符合了这样的应用场景。
为了避免并查集所表示的树形结构高度过高,影响查询性能。「路径压缩」就是针对树的高度的优化。「路径压缩」的效果是:在查询一个结点 a 的根结点同时,把结点 a 到根结点的沿途所有结点的父亲结点都指向根结点。如下图所示,除了根结点以外,所有的结点的父亲结点都指向了根结点。特别地,也可以认为根结点的父亲结点就是根结点自己。如下国所示:路径压缩前后,并查集所表示的两棵树形结构等价,路径压缩以后的树的高度为 $2$,查询性能最好。
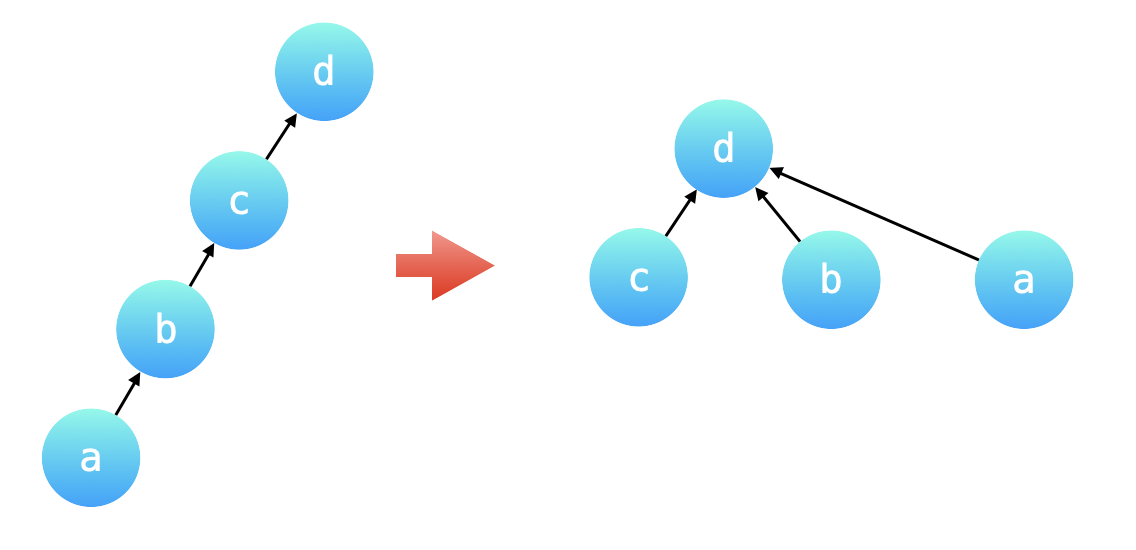 {:width=400}
{:width=400}
由于有「路径压缩」的优化,两个同在一个连通分量中的不同的变量,它们分别到根结点(父亲结点)的权值的比值,就是题目的要求的结果。
如何在「查询」操作的「路径压缩」优化中维护权值变化
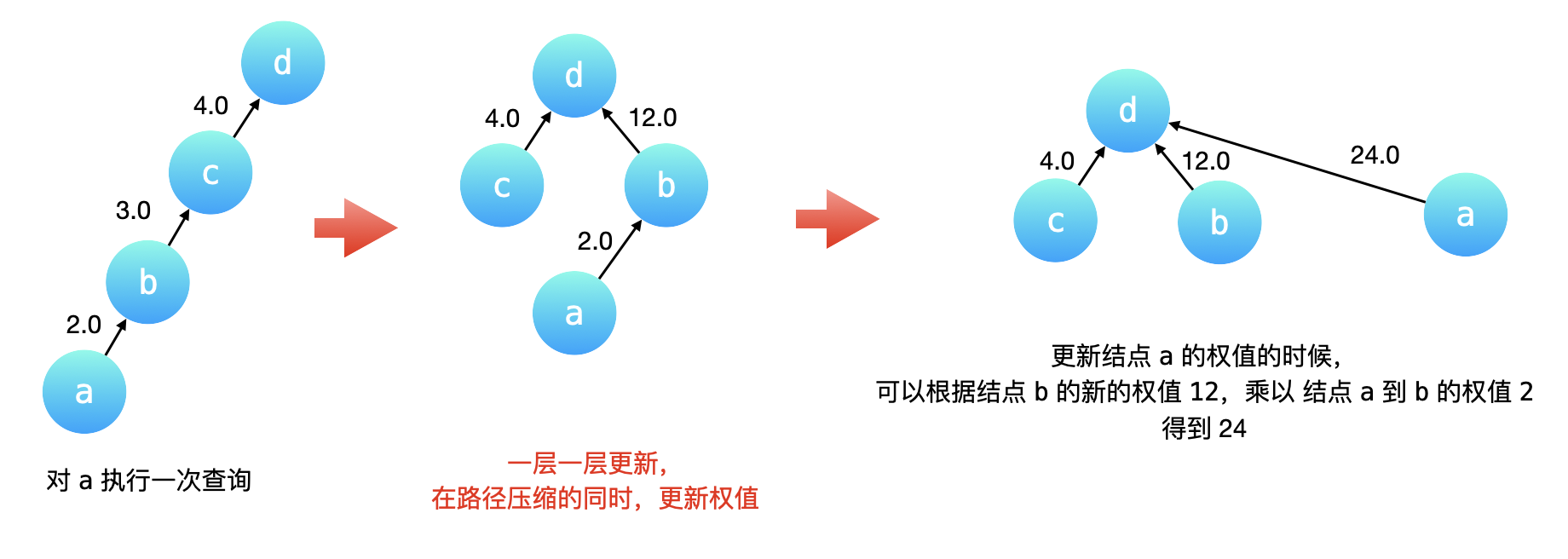
如下图所示,我们在结点 a 执行一次「查询」操作。路径压缩会先一层一层向上先找到根结点 d,然后依次把 c、b 、a 的父亲结点指向根结点 d。
c的父亲结点已经是根结点了,它的权值不用更改;b的父亲结点要修改成根结点,它的权值就是从当前结点到根结点经过的所有有向边的权值的乘积,因此是 $3.0$ 乘以 $4.0$ 也就是 $12.0$;a的父亲结点要修改成根结点,它的权值就是依然是从当前结点到根结点经过的所有有向边的权值的乘积,但是我们 没有必要把这三条有向边的权值乘起来,这是因为b到c,c到d这两条有向边的权值的乘积,我们在把b指向d的时候已经计算出来了。因此,a到根结点的权值就等于b到根结点d的新的权值乘以a到b的原来的有向边的权值。
如何在「合并」操作中维护权值的变化
「合并」操作基于这样一个 很重要的前提:我们将要合并的两棵树的高度最多为 $2$,换句话说两棵树都必需是「路径压缩」以后的效果,两棵树的叶子结点到根结点最多只需要经过一条有向边。
例如已知 $\cfrac{a}{b} = 3.0$,$\cfrac{d}{c} = 4.0$ ,又已知 $\cfrac{a}{d} = 6.0$ ,现在合并结点 a 和 d 所在的集合,其实就是把 a 的根结点 b 指向 d 的根结 c,那么如何计算 b 指向 c 的这条有向边的权重呢?
根据 a 经过 b 可以到达 c,a 经过 d 也可以到达 c,因此 两条路径上的有向边的权值的乘积是一定相等的。设 b 到 c 的权值为 $x$,那么 $3.0 \cdot x = 6.0 \cdot 4.0$ ,得 $x = 8.0$。
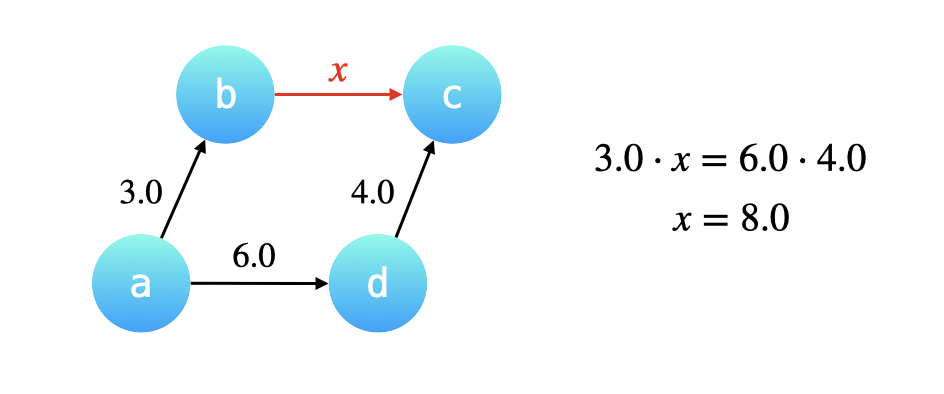 {:width=400}
{:width=400}
一个容易忽略的细节
接下来还有一个小的细节问题:在合并以后,产生了一棵高度为 $3$ 的树,那么我们在执行查询的时候,例如下图展示的绿色结点和黄色结点,绿色结点并不直接指向根结点,在计算这两个变量的比值的时候,计算边的权值的比值得到的结果是不对的。
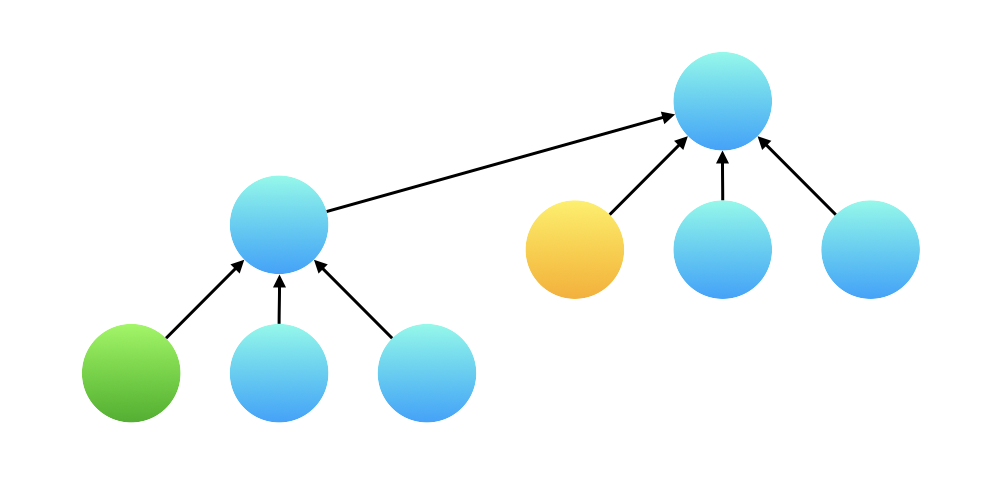 {:width=400}
{:width=400}
但其实不用担心这个问题,并查集的「查询」操作会执行「路径压缩」,所以真正在计算两个变量的权值的时候,绿色结点已经指向了根结点,和黄色结点的根结点相同。因此可以用它们指向根结点的有向边的权值的比值作为两个变量的比值。
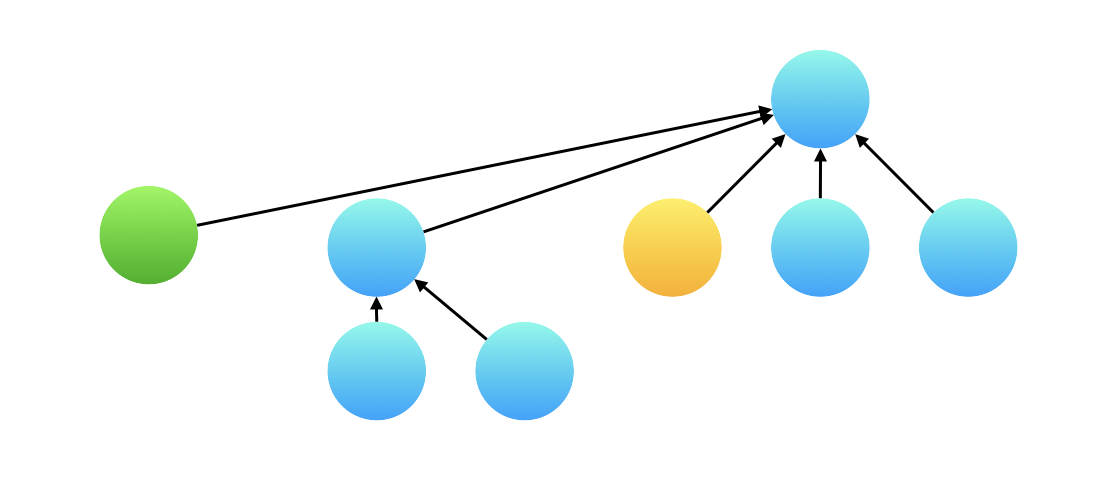 {:width=400}
{:width=400}
我们通过这个细节向大家强调:一边查询一边修改结点指向是并查集的特色。
参考代码:
1 | import java.util.HashMap; |
说明:代码 weight[rootX] = weight[y] * value / weight[x]; 的推导过程,主要需要明白各个变量的含义,由两条路径有向边的权值乘积相等得到相等关系,然后做等价变换即可。
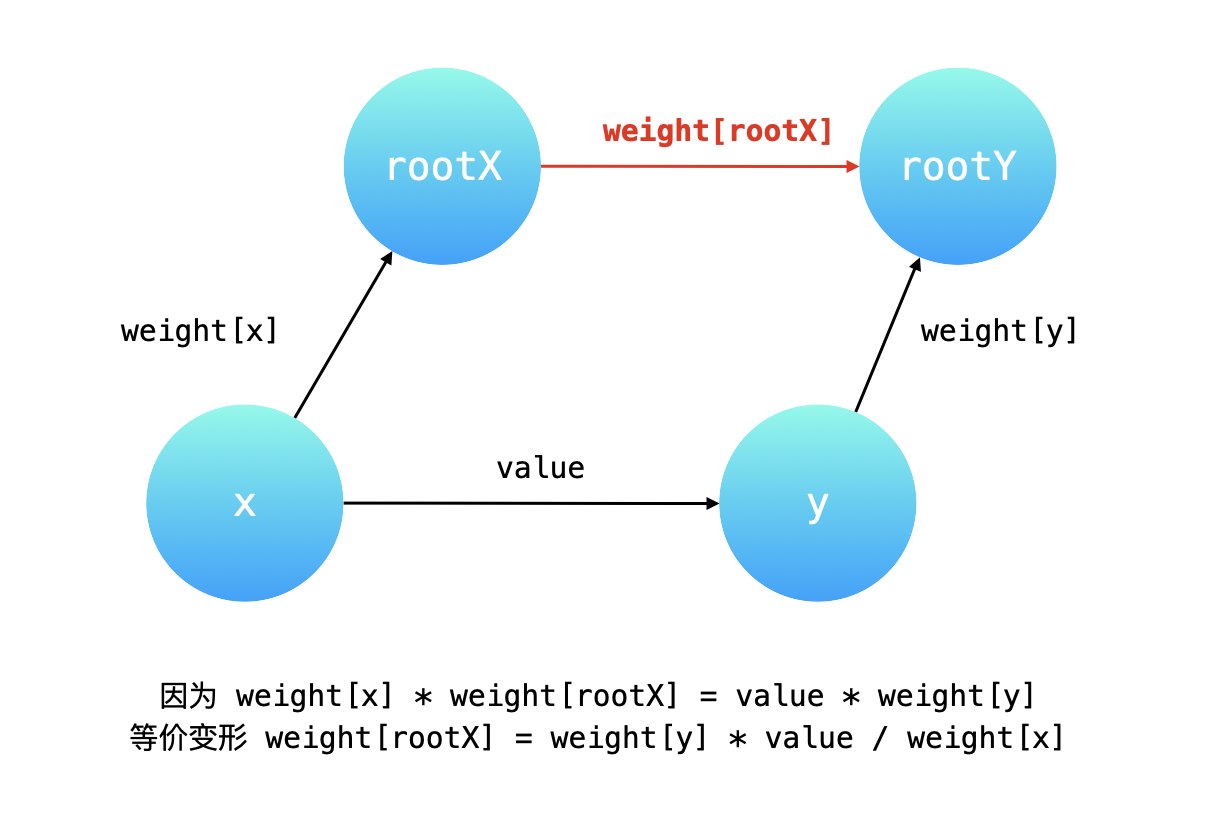 {:width=500}
{:width=500}
复杂度分析:
时间复杂度:$O((N + Q)\log A)$,
- 构建并查集 $O(N \log A)$ ,这里 $N$ 为输入方程
equations的长度,每一次执行合并操作的时间复杂度是 $O(\log A)$,这里 $A$ 是equations里不同字符的个数; - 查询并查集 $O(Q \log A)$,这里 $Q$ 为查询数组
queries的长度,每一次查询时执行「路径压缩」的时间复杂度是 $O(\log A)$。
- 构建并查集 $O(N \log A)$ ,这里 $N$ 为输入方程
空间复杂度:$O(A)$:创建字符与
id的对应关系hashMap长度为 $A$,并查集底层使用的两个数组parent和weight存储每个变量的连通分量信息,parent和weight的长度均为 $A$。