0736-Lisp 语法解析
给你一个类似 Lisp 语句的字符串表达式 expression,求出其计算结果。
表达式语法如下所示:
- 表达式可以为整数, let 表达式, add 表达式, mult 表达式,或赋值的变量。表达式的结果总是一个整数。
- (整数可以是正整数、负整数、0)
- let 表达式采用
"(let v1 e1 v2 e2 ... vn en expr)"的形式,其中let总是以字符串"let"来表示,接下来会跟随一对或多对交替的变量和表达式,也就是说,第一个变量v1被分配为表达式e1的值,第二个变量v2被分配为表达式e2的值, 依次类推 ;最终let表达式的值为expr表达式的值。 - add 表达式表示为
"(add e1 e2)",其中add总是以字符串"add"来表示,该表达式总是包含两个表达式e1、e2,最终结果是e1表达式的值与e2表达式的值之 和 。 - mult 表达式表示为
"(mult e1 e2)",其中mult总是以字符串"mult"表示,该表达式总是包含两个表达式e1、e2,最终结果是e1表达式的值与e2表达式的值之 积 。 - 在该题目中,变量名以小写字符开始,之后跟随 0 个或多个小写字符或数字。为了方便,
"add","let","mult"会被定义为 “关键字” ,不会用作变量名。 - 最后,要说一下作用域的概念。计算变量名所对应的表达式时,在计算上下文中,首先检查最内层作用域(按括号计),然后按顺序依次检查外部作用域。测试用例中每一个表达式都是合法的。有关作用域的更多详细信息,请参阅示例。
示例 1:
**输入:** expression = "(let x 2 (mult x (let x 3 y 4 (add x y))))"
**输出:** 14
**解释:**
计算表达式 (add x y), 在检查变量 x 值时,
在变量的上下文中由最内层作用域依次向外检查。
首先找到 x = 3, 所以此处的 x 值是 3 。
示例 2:
**输入:** expression = "(let x 3 x 2 x)"
**输出:** 2
**解释:** let 语句中的赋值运算按顺序处理即可。
示例 3:
**输入:** expression = "(let x 1 y 2 x (add x y) (add x y))"
**输出:** 5
**解释:**
第一个 (add x y) 计算结果是 3,并且将此值赋给了 x 。
第二个 (add x y) 计算结果是 3 + 2 = 5 。
提示:
1 <= expression.length <= 2000exprssion中不含前导和尾随空格expressoin中的不同部分(token)之间用单个空格进行分隔- 答案和所有中间计算结果都符合 32-bit 整数范围
- 测试用例中的表达式均为合法的且最终结果为整数
方法一:递归解析
对于一个表达式 expression,如果它的首字符不等于左括号 `(‘,那么它只能是一个整数或者变量;否则它是 let,add 和 mult 三种表达式之一。
定义函数 parseVar 用来解析变量以及函数 parseInt 用来解析整数。使用 scope 来记录作用域,每个变量都依次记录下它从外到内的所有值,查找时只需要查找最后一个数值。我们递归地解析表达式 expression。
expression 的下一个字符不等于左括号 `(‘。
expression 的下一个字符是小写字母,那么表达式是一个变量,使用函数 parseVar 解析变量,然后在 scope 中查找变量的最后一个数值即最内层作用域的值并返回结果。
expression 的下一个字符不是小写字母,那么表达式是一个整数,使用函数 parseInt 解析并返回结果。
去掉左括号后,expression 的下一个字符是 `l’,那么表达式是 let 表达式。对于 let 表达式,需要判断是否已经解析到最后一个 expr 表达式。
如果下一个字符不是小写字母,或者解析变量后下一个字符是右括号 `)’,说明是最后一个 expr 表达式,计算它的值并返回结果。并且我们需要在 scope 中清除 let 表达式对应的作用域变量。
否则说明是交替的变量 v_i 和表达式 e_i,在 scope 将变量 v_i 的数值列表增加表达式 e_i 的数值。
去掉左括号后,expression 的下一个字符是 `a’,那么表达式是 add 表达式。计算 add 表达式对应的两个表达式 e_1 和 e_2 的值,返回两者之和。
去掉左括号后,expression 的下一个字符是 `m’,那么表达式是 mult 表达式。计算 mult 表达式对应的两个表达式 e_1 和 e_2 的值,返回两者之积。
代码
1 | class Solution: |
1 | class Solution { |
1 | class Solution { |
1 | public class Solution { |
1 | typedef struct { |
1 | func evaluate(expression string) int { |
1 | var evaluate = function(expression) { |
复杂度分析
时间复杂度:O(n),其中 n 是字符串 expression 的长度。递归调用函数 innerEvaluate 在某一层调用的时间复杂度为 O(k),其中 k 为指针 start 在该层调用的移动次数。在整个递归调用过程中,指针 start 会遍历整个字符串,因此解析 expression 需要 O(n)。
空间复杂度:O(n)。保存 scope 以及递归调用栈需要 O(n) 的空间。
方法二:状态机
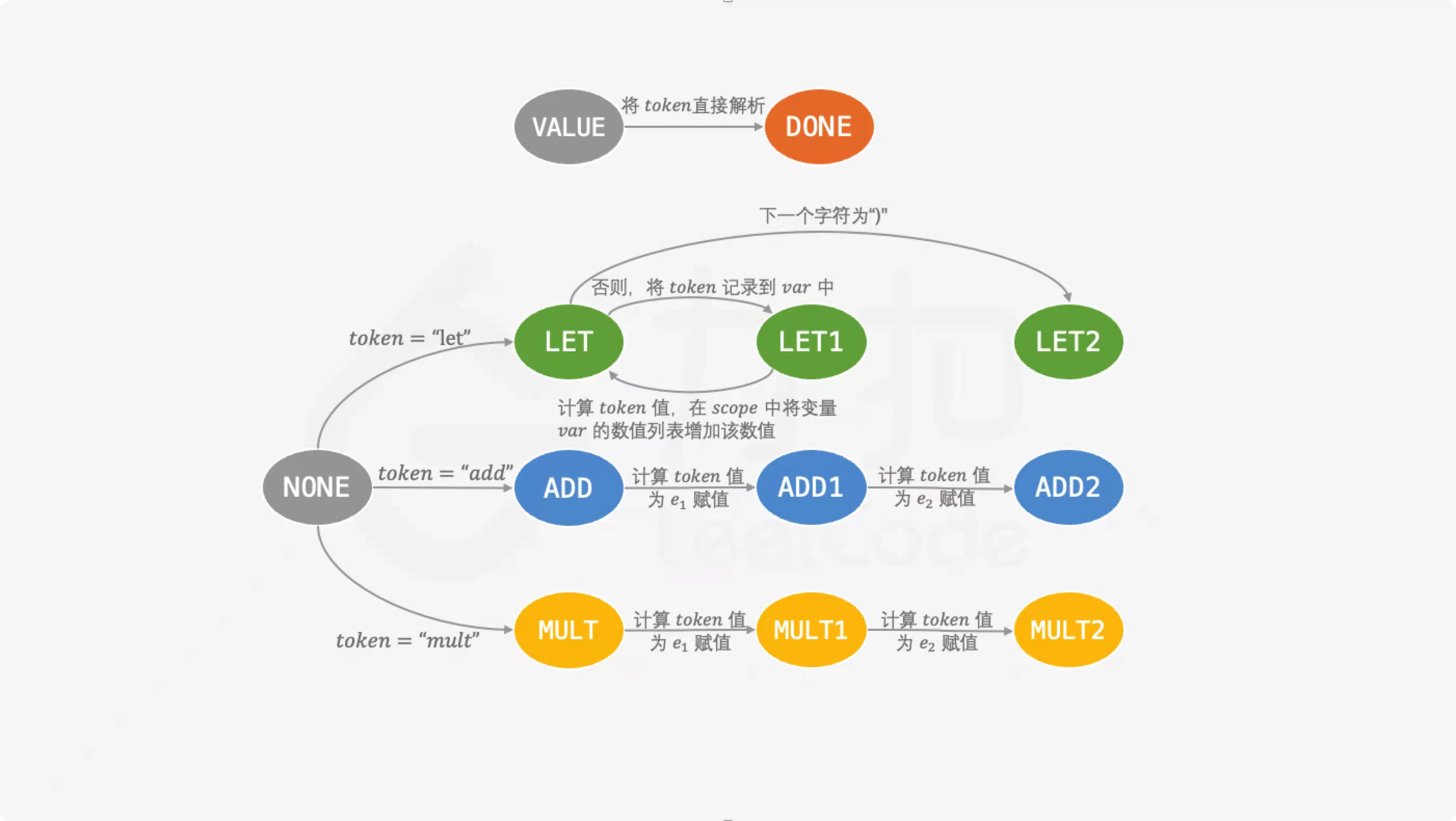
定义状态 ExprStatus,状态机的初始状态 cur 为 VALUE。
当我们解析到一个左括号时,我们需要将当前状态 cur 压入栈中,然后将当前状态 cur 设为状态 NONE,表示对一个未知表达式的解析。当我们解析到一个右括号时,我们需要根据括号对应的表达式的类型来计算最终值,并且将它转换成一个 token 传回上层状态,将上层状态出栈并设为当前状态 cur,对于 let 表达式,我们还需要清除它的作用域。
以下的每次状态的转换都会伴随一个 token,其中 token 表示被空格和括号分隔开的词块,并且 let,add 和 mult 三种表达式都可以转换成一个整数 token。状态转换如下:
状态 VALUE:
- 将 token 直接解析成整数保存到 value 中,并将状态设为 DONE,标志解析完成。
状态 NONE:
token} = \text{``let”:将当前状态 cur 设为 LET。
token} = \text{``add”:将当前状态 cur 设为 ADD。
token} = \text{``mult”:将当前状态 cur 设为 MULT。
状态 LET:
下一个字符是右括号,说明已经到达 let 表达式的最后一个 expr 表达式,计算 token 的值并保存到 value,并且将当前状态 cur 设为 LET2,标志着 let 表达式的解析完成。
下一个字符不是右括号,将 token 记录到 var 中,并且将当前状态 cur 设为 LET1。
状态 LET1:
- 计算 token 的值,在 scope 中将变量 var 的数值列表增加该数值,并且将当前状态 cur 设为 LET。
状态 ADD:
- 计算 token 的值,为 e_1 赋值,并且将当前状态 cur 设为 ADD1。
状态 ADD1:
- 计算 token 的值,为 e_2 赋值,并且将当前状态 cur 设为 ADD2,标志着 add 表达式的解析完成。
状态 MULT:
- 计算 token 的值,为 e_1 赋值,并且将当前状态 cur 设为 MULT1。
状态 MULT1:
- 计算 token 的值,为 e_2 赋值,并且将当前状态 cur 设为 MULT2,标志着 mult 表达式的解析完成。
状态机有两种转换路线,第一种是从 VALUE 到 DONE 的转换路线,第二种是从 NONE 到 LET2,ADD2 或 MULT2 的转换路线。
代码
1 | from enum import Enum, auto |
1 | enum ExprStatus { |
1 | class Solution { |
1 | public class Solution { |
1 |
|
1 | const ( |
1 | var evaluate = function(expression) { |
复杂度分析
时间复杂度:O(n),其中 n 是字符串 expression 的长度。状态机解析会遍历整个字符串,因此需要 O(n) 的时间。
空间复杂度:O(n)。保存状态的栈以及作用域变量都需要 O(n) 的空间。